Copyright © 2011 ASIPTO
Abstract
This book documents the internal architecture of Kamailio SIP Server, providing the details useful to develop extensions in the core or as a module.
The focus will be on major components of the SIP server, such as memory manager, locking system, parser, database API, configuration file, MI commands, pseudo-variables and module interface.
Examples, API and the architecture are based on current stable version of Kamailio - 3.2.0 - at October 30, 2011. It is also valid for development version - 3.3.0 - at this date. The document will be timely updated accordingly, check for updates at www.asipto.com or www.kamailio.org.
This document is free to use for anybody. The authors are not liable in any way for the consequences you may get due to usage of this document.
Table of Contents
- 1. Introduction
- 2. Kamailio Architecture
- 3. Locking system
- 4. Memory Manager
- 5. Data structures
- 6. SIP Parser
- 7. Transport Layer
- 8. Extending configuration file
- 9. Database API
- 9.1. DB1 API Structure
- 9.2. DB1 API Functions
- 9.2.1. Function init(...)
- 9.2.2. Function close(...)
- 9.2.3. Function use_table(...)
- 9.2.4. Function query(...)
- 9.2.5. Function fetch_result(...)
- 9.2.6. Function raw_query(...)
- 9.2.7. Function free_result(...)
- 9.2.8. Function insert(...)
- 9.2.9. Function delete(...)
- 9.2.10. Function update(...)
- 9.2.11. Function replace(...)
- 9.2.12. Function last_inserted_id(...)
- 9.2.13. Function insert_update(...)
- 9.2.14. Function insert_delayed(...)
- 9.2.15. Function affected_rows(...)
- 9.3. DB API Data Types
- 9.4. Macros
- 9.5. Example of usage
- 10. RPC and MI Control Interfaces
- 11. Pseudo-variables
- 12. Transformations
- 13. Statistics
- 14. Data Lumps
- 15. Timer
- 16. Module Development
- 16.1. module_exports type
- 16.2. cmd_export_t type
- 16.3. param_export_t type
- 16.4. proc_export_t type
- 16.5. stat_export_t type
- 16.6. pv_export_t
- 16.7. Functions Types
- 16.8. Command Functions
- 16.9. Developing a new module
- 16.9.1. Naming the module
- 16.9.2. Module Makefile
- 16.9.3. Main File
- 16.9.4. Add Module Parameter
- 16.9.5. Module Init Function
- 16.9.6. Module Child Init Function
- 16.9.7. Module Destroy Function
- 16.9.8. Add Command Function
- 16.9.9. Add Pseudo-Variable
- 16.9.10. Add MI Command
- 16.9.11. Add Extra Process
- 16.9.12. CFGUTILS module_exports
- 16.10. Upgrading modules from v1.x to v3.x
- 17. Internal Library Development
- 18. Licensing
- 19. References
- 20. Contact Details
List of Figures
In June 2005, Kamailio was born as a split from SIP Express Router (aka SER) project of FhG FOKUS Institute, Berlin, Germany. The newly created project was aiming to create an open development environment to build robust and scalable open source SIP server. Initial name was OpenSER, but due to trademark infringements claims, the project name changed from OpenSER to Kamailio on July 28, 2008.
The website of the project is http://www.kamailio.org. The source code up to version 1.5.x was hosted on sourceforge.net SVN repository. Starting with version 3.0.0, the source code is hosted on sip-router.org GIT repository.
In November 2008, the development teams of Kamailio and SIP Express Router (SER) joined again their efforts and started to work together to integrate the two SIP server applications. The integration concluded with release of v3.0.0, which represents a single source code tree for both applications. In other words, Kamailio and SER are the same application from source code point of view, the difference is done by the name chosen to build the application and the modules loaded in the default configuration file.
The evolution in time of Kamailio is presented in next figure.
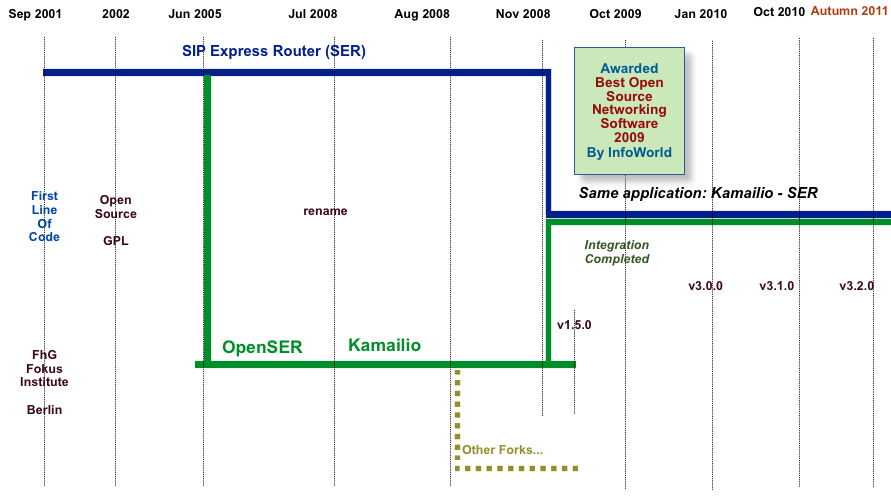
Today Kamailio SIP Server is a reference implementation, featuring hundreds of VoIP services world wide, being developed by people around the world. It is included in official distributions of several Linux and BSD flavors.
The number of registered developers and packagers exceeded 90 since the start of the project in 2001. During the last year, over 30 registered developers contributed code to project. The level of contributions and the amount of contributors has an important impact on the evolution of the project. The book tries to ease the understanding of Kamailio from a developer point of view, giving the kick start knowledge, it does not intend to be a cookbook. Efforts to improve the documentation in the sources is undertaken and make it doxygen compliant, making a good developer documentation out of there.
Daniel-Constantin Mierla is one of the co-founders of Kamailio SIP Server project. He is involved in VoIP and SIP since beginning of 2002, at FhG FOKUS Institute, Berlin, Germany, being core developer in the SIP Express Router project. Currently he is employed by ASIPTO, a Kamailio-focused company. Daniel is an active Kamailio developer, member of management board, leading the project.
Elena-Ramona Modroiu is one of the co-founders of Kamailio SIP Server project. She got involved in VoIP and SIP while working at her graduation thesis within SIP Express Router (SER) project at FhG FOKUS Institute. She completed studies at Polytechnic University of Valencia and Siemens Germany, working now at ASIPTO, being an active developer and member of management board of Kamailio.
The two authored many online tutorials about Kamailio, among them: Kamailio Core Cookbook, Kamailio Transformations Cookbook, Kamailio Pseudo-Variables Cookbook, Kamailio and Asterisk Integration, Kamailio and FreeSWITCH Integration, SIP Routing in Lua with Kamailio, Secure VoIP with Kamailio, IPv4 - IPv6 VoIP bridging with Kamailio, Kamailio and FreeRADIUS.
This document is focusing only to Kamailio specific API, has no intention to teach C programing for Linux and Networking. You, as a reader, should have already the basic knowledge of C programming.
Do not contact the authors to ask about standard C functions or variables.
There are many references to parts of code in the source tree. You must be familiar with the directory structure of Kamailio. It is not our intention to explain how something was implemented, but how to use existing code to extend Kamailio easily.
The source code remains the best reference for developers. In the last time, the comments around the important functions in Kamailio have been improved and converted to doxygen format. You should double-check the source code if the prototype of the functions presented in this document are still valid.
Daily updated doxygen documentation is available at http://devel.kamailio.org/doxygen/.
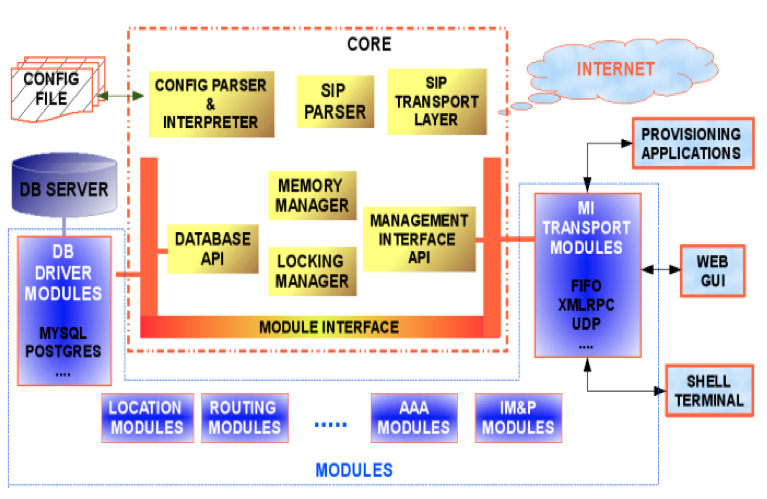
Kamailio has a modular architecture. As a big picture, there are two main categories:
the core - it is the component that provides the low-level functionalities for Kamailio.
Starting with version 3.0.0, Kamailio core includes so called internal libraries. They collect code shared by several modules but which does not have a general purpose to be part of main core.
the modules - are the components that provides the most of the functionalities that make Kamailio powerful in real world deployments.
The architecture for Kamailio v1.5.x (or older) is shown in the next figure.
The architecture for Kamailio v3.0.x (or newer) was refactored, permitting to have code shared by several modules stored in internal libraries. Some of the core components in v1.x being relocated as an internal library. The new architecture for v3.0.x compared with the one from v1.x is shown in the next figure.
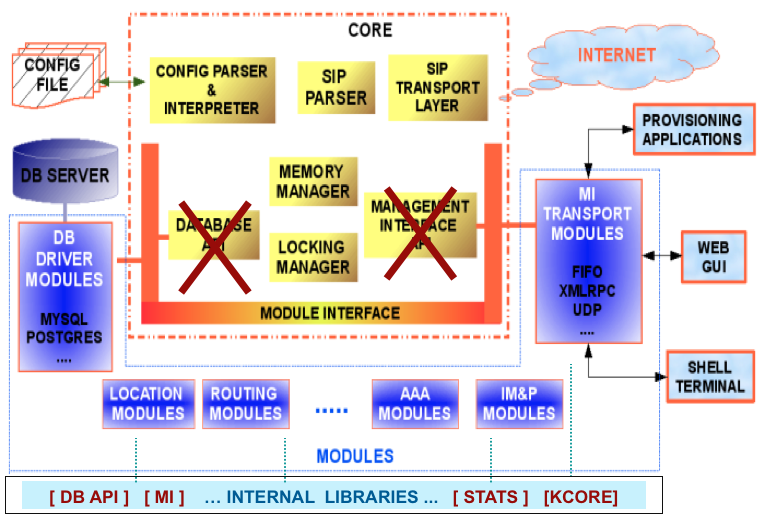
The core includes:
memory manager
SIP message parser
locking system
DNS and transport layer management (UDP, TCP, TLS, SCTP)
configuration file parser and interpreter
stateless forwarding
pseudo-variables and transformations engines
RPC control interface API
timer API
The internal libraries include:
some components from old Kamailio v1.5.x core
database abstraction layers (DB API v1 and v2)
management interface (MI) API
statistics engine
There are over 150 modules in the repository at this moment. By loading modules, you can get functionalities such as:
registrar and user location management
accounting, authorization and authentication
text and regular expression operations
stateless replying
stateful processing - SIP transaction management
SIP dialogs tracking - active calls management
instant messaging and presence extensions
RADIUS and LDAP support
SQL and no-SQL database connectors
MI and RPC transports
Enum, GeoIP API and CPL interpreter
topology hiding and NAT traversal
load balancing and least cost routing
asynchronous SIP request processing
interactive configuration file debugger
Lua, Perl, Python and Java SIP Servlet extensions
The execution of Kamailio configuration file is triggered when receiving a SIP message from the network. The processing flow is different for a SIP request or a SIP reply.
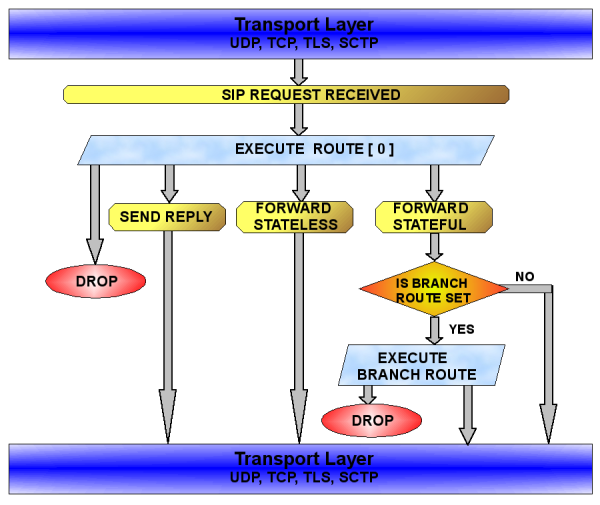
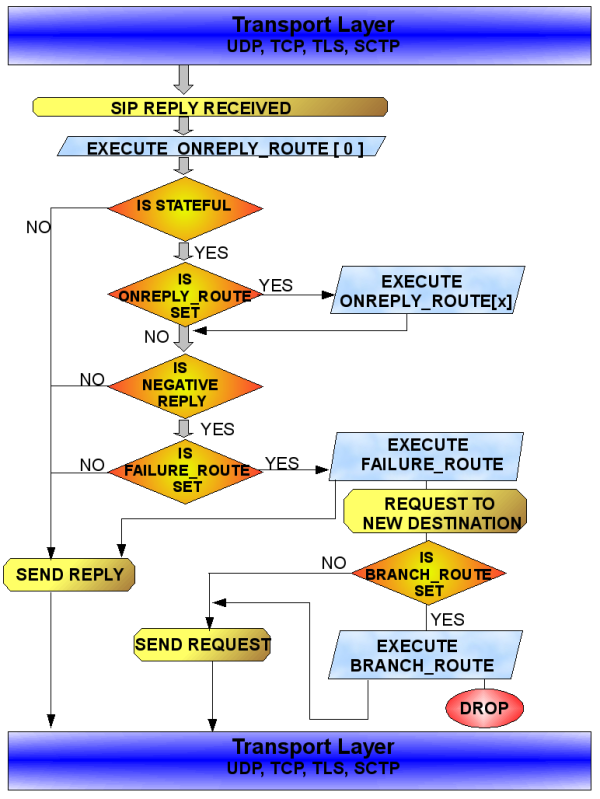
The document contains a chapter dedicated to Configuration File that explains its structure and the types of routing blocks.
Kamailio provides a custom locking system which has a simple interface for development. Its root element is a mutex semaphore, that can be set (locked) or unset (unlocked). The rest of synchronization mechanisms available in SysV and POSIX not being needed.
The locks can be used as simple variables or lock sets (array of simple locks). To improve the speed, behind the locks is, by default, machine-specific code. If the architecture of the machine is unknown, Kamailio will use SysV semaphores.
Basically, to create a lock, you have to define a variable of type gen_lock_t, allocate it in shared memory and initialize it. Then you can perform set/unset operations, destroying the variable when you finish using it.
To use the locking system in your C code you have to include the headers file: locking.h.
Data types and available functions to do operations with locks are described in the next sections.
It is the type to define a lock variable. It must be allocated in shared memory, to be available across Kamailio processes.
Allocates a lock in shared memory. If your gen_lock_t is not part of a structure allocated in shared memory, you have to use this function to properly create the lock.
It returns the pointer to a shared memory structure.
Example 3.3. Example of usage
...
#include "locking.h"
...
gen_lock_t *lock;
lock = lock_alloc();
if(lock==NULL)
{
LM_ERR("cannot allocate the lock\n");
exit;
}
...
Lock allocation can be skipped if the lock is already in shared memory -- BUT be sure the lock content IS in shared memory.
Example 3.4. Example of lock in shared memory
...
struct s {
int a;
gen_lock_t lock;
} *x;
x = shm_malloc(sizeof struct s); /* we allocate it in the shared memory */
if (lock_init(&x->lock)==0){
/* error initializing the lock */
...
}
...
Free the shared memory allocated for lock.
The parameter is a variable returned by lock_alloc(...).
Example 3.6. Example of usage
...
#include "locking.h"
...
gen_lock_t *lock;
lock = lock_alloc();
if(lock==NULL)
{
LM_ERR("cannot allocate the lock\n");
exit;
}
/* make use of lock */
...
lock_dealloc(lock);
...
Initialize the lock. You must call this function before the first set operation on the lock.
It returns the parameter if there is no error, NULL if error occurred.
Example 3.8. Example of usage
...
#include "locking.h"
...
gen_lock_t *lock;
lock = lock_alloc();
if(lock==NULL)
{
LM_ERR("cannot allocate the lock\n");
exit;
}
if(lock_init(lock)==NULL)
{
LM_ERR("cannot init the lock\n");
lock_dealloc(lock);
exit;
}
/* make use of lock */
...
lock_dealloc(lock);
...
Destroy internal attributes of gen_lock_t. You must call it before deallocating a lock to ensure proper clean up (if SysV is used, it calls the functions to remove the semaphores).
The parameter is a lock initialized with lock_init(...).
Example 3.10. Example of usage
...
#include "locking.h"
...
gen_lock_t *lock;
lock = lock_alloc();
if(lock==NULL)
{
LM_ERR("cannot allocate the lock\n");
exit;
}
if(lock_init(lock)==NULL)
{
LM_ERR("cannot init the lock\n");
lock_dealloc(lock);
exit;
}
/* make use of lock */
...
lock_destroy(lock);
lock_dealloc(lock);
...
Perform set operation on a lock. If the lock is already set, the function waits until the lock is unset.
The parameter must be initialized with lock_init(...) before calling this function.
Example 3.12. Example of usage
...
#include "locking.h"
...
gen_lock_t *lock;
lock = lock_alloc();
if(lock==NULL)
{
LM_ERR("cannot allocate the lock\n");
exit;
}
if(lock_init(lock)==NULL)
{
LM_ERR("cannot init the lock\n");
lock_dealloc(lock);
exit;
}
/* make use of lock */
lock_get(lock);
/* under lock protection */
...
lock_destroy(lock);
lock_dealloc(lock);
...
Try to perform set operation on a lock. If the lock is already set, the function returns -1, otherwise sets the lock and returns 0. This is a non-blocking lock_get().
The parameter must be initialized with lock_init(...) before calling this function.
Example 3.14. Example of usage
...
#include "locking.h"
...
gen_lock_t *lock;
lock = lock_alloc();
if(lock==NULL)
{
LM_ERR("cannot allocate the lock\n");
exit;
}
if(lock_init(lock)==NULL)
{
LM_ERR("cannot init the lock\n");
lock_dealloc(lock);
exit;
}
/* make use of lock */
if(lock_try(lock)==0) {
/* under lock protection */
...
} else {
/* NO lock protection */
...
}
...
lock_destroy(lock);
lock_dealloc(lock);
...
Perform unset operation on a lock. If the lock is set, it will unblock it. You should call it after lock_set(...), after finishing the operations that needs synchronization and protection against race conditions.
The parameter must be initialized before calling this function.
Example 3.16. Example of usage
...
#include "locking.h"
...
gen_lock_t *lock;
lock = lock_alloc();
if(lock==NULL)
{
LM_ERR("cannot allocate the lock\n");
exit;
}
if(lock_init(lock)==NULL)
{
LM_ERR("cannot init the lock\n");
lock_dealloc(lock);
exit;
}
/* make use of lock */
lock_get(lock);
/* under lock protection */
...
lock_release(lock);
...
lock_destroy(lock);
lock_dealloc(lock);
...
The lock set is an array of gen_lock_t. To create a lock set, you have to define a variable of type gen_lock_set_t, allocate it in shared memory specifying the number of locks in the set, then initialize it. You can perform set/unset operations, providing the lock set variable and destroying the variable when you finish using it.
To use the lock sets in your C code you have to include the headers file: locking.h.
Data types and available functions to do operations with lock sets are described in the next sections.
It is the type to define a lock set variable. It must be allocated in shared memory, to be available across Kamailio processes.
Allocates a lock set in shared memory.
The parameter n specifies the number of locks in the set. Return pointer to the lock set, or NULL if the set couldn't be allocated.
Example 3.19. Example of usage
...
#include "locking.h"
...
gen_lock_set_t *set;
set = lock_set_alloc(16);
if(set==NULL)
{
LM_ERR("cannot allocate the lock set\n");
exit;
}
...
Free the memory allocated for a lock set.
The parameter has to be a lock set allocated with lock_set_alloc(...).
Example 3.21. Example of usage
...
#include "locking.h"
...
gen_lock_set_t *set;
set = lock_set_alloc(16);
if(set==NULL)
{
LM_ERR("cannot allocate the lock set\n");
exit;
}
...
lock_set_dealloc(set);
...
Initialized the internal attributes of a lock set. The lock set has to be allocated with lock_set_alloc(...). This function must be called before performing any set/unset operation on lock set.
The parameter is an allocated lock set. It returns NULL if the lock set couldn't be initialized, otherwise returns the pointer to the lock set.
Example 3.23. Example of usage
...
#include "locking.h"
...
gen_lock_set_t *set;
set = lock_set_alloc(16);
if(set==NULL)
{
LM_ERR("cannot allocate the lock set\n");
exit;
}
if(lock_set_init(set)==NULL)
{
LM_ERR("cannot initialize the lock set'n");
lock_set_dealloc(set);
exit;
}
/* make usage of lock set */
...
lock_set_dealloc(set);
...
Destroy the internal structure of the lock set. You have to call it once you finished to use the lock set. The function must be called after lock_set_init(...)
The parameter is an initialized lock set. After calling this function you should not perform anymore set/unset operations on lock set.
Example 3.25. Example of usage
...
#include "locking.h"
...
gen_lock_set_t *set;
set = lock_set_alloc(16);
if(set==NULL)
{
LM_ERR("cannot allocate the lock set\n");
exit;
}
if(lock_set_init(set)==NULL)
{
LM_ERR("cannot initialize the lock set'n");
lock_set_dealloc(set);
exit;
}
/* make usage of lock set */
...
lock_set_destroy(set);
lock_set_dealloc(set);
...
Set (block) a lock in the lock set. You should call this function after the lock set has been initialized. If the lock is already set, the function waits until that lock is unset (unblocked).
First parameter is the lock set. The second is the index withing the set of the lock to be set. First lock in set has index 0. The index parameter must be between 0 and n-1 (see lock_set_alloc(...).
Example 3.27. Example of usage
...
#include "locking.h"
...
gen_lock_set_t *set;
set = lock_set_alloc(16);
if(set==NULL)
{
LM_ERR("cannot allocate the lock set\n");
exit;
}
if(lock_set_init(set)==NULL)
{
LM_ERR("cannot initialize the lock set'n");
lock_set_dealloc(set);
exit;
}
/* make usage of lock set */
lock_set_get(set, 8);
/* under lock protection */
...
lock_set_destroy(set);
lock_set_dealloc(set);
...
Try to set (block) a lock in the lock set. You should call this function after the lock set has been initialized. If the lock is already set, the function returns -1, otherwise it sets the lock and returns 0. This is a non-blocking lock_set_get().
First parameter is the lock set. The second is the index withing the set of the lock to be set. First lock in set has index 0. The index parameter must be between 0 and n-1 (see lock_set_alloc(...).
Example 3.29. Example of usage
...
#include "locking.h"
...
gen_lock_set_t *set;
set = lock_set_alloc(16);
if(set==NULL)
{
LM_ERR("cannot allocate the lock set\n");
exit;
}
if(lock_set_init(set)==NULL)
{
LM_ERR("cannot initialize the lock set'n");
lock_set_dealloc(set);
exit;
}
/* make usage of lock set */
if(lock_set_try(set, 8)==0) {
/* under lock protection */
...
} else {
/* NO lock protection */
...
}
...
lock_set_destroy(set);
lock_set_dealloc(set);
...
Unset (unblock) a lock in the lock set.
First parameter is the lock set. The second is the index withing the set of the lock to be unset. First lock in set has index 0. The index parameter must be between 0 and n-1 (see lock_set_alloc(...).
Example 3.31. Example of usage
...
#include "locking.h"
...
gen_lock_set_t *set;
set = lock_set_alloc(16);
if(set==NULL)
{
LM_ERR("cannot allocate the lock set\n");
exit;
}
if(lock_set_init(set)==NULL)
{
LM_ERR("cannot initialize the lock set'n");
lock_set_dealloc(set);
exit;
}
/* make usage of lock set */
lock_set_get(set, 8);
/* under lock protection */
...
lock_set_release(set, 8);
...
lock_set_destroy(set);
lock_set_dealloc(set);
...
A clear sign of issues with the locking is that one or more Kamailio processes eat lot of CPU. If the traffic load does not justify such behavior and no more SIP messages are processed, the only solution is to troubleshoot and fix the locking error. The problem is that a lock is set but never unset. A typical case is when returning due to an error and forgetting to release a previously lock set.
To troubleshoot a solution is to use gdb, attach to the process that eats lot of CPU and get the backtrace. You need to get the PID of that Kamailio process - top or ps tools can be used.
... # gdb /path/to/kamailio PID # gdb> bt ...
From the backtrace you should get to the lock that is set and not released. From there you should start the investigation - what are the cases to set that lock and in which circumstances it does not get released.
As Kamailio is a multi-process application, the usage of shared memory is required in many scenarios. The memory manager tries to simplify the work with shared and private memory, providing a very simple programming interface. The internal design took in consideration speed optimizations, something very important for a real-time communication server.
The manager is initialized at start-up, creating the chunks for private and shared memory. It is important to know that the shared memory is not available during configuration parsing, that includes the setting of module parameters.
When the own memory manager cannot be used, Kamailio falls back to the SysV shared memory system.
Shortly, the manager reserves a big chunk of system memory for itself at start-up, then it allocates parts inside the chunk as visible in the following figure.
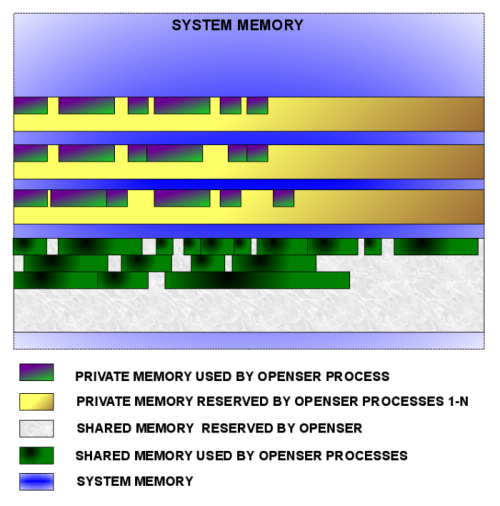
This type of memory is specific per process, no synchronization is needed to access structures allocated in it. It should be used for variables that do not need to be visible in other Kamailio processes or for temporary operations.
To store static values in private memory and have it in all processes without the need to synchronize for accessing it, you must create it before Kamailio forks.
To use the private memory manager you have to include the file: mem/mem.h.
Allocates space in private memory.
The parameter specifies the size of memory space to be allocated. Returns the pointer to memory if the the operation succeeds, NULL otherwise.
Example 4.2. Example of usage
...
#include "mem/mem.h"
...
char *p;
p = (char*)pkg_malloc(8*sizeof(char));
if(p==NULL)
{
LM_ERR("cannot allocate pkg memory\n");
exit;
}
...
Free allocated private memory.
The parameter is the pointer to the memory to be freed.
Example 4.4. Example of usage
...
#include "mem/mem.h"
...
char *p;
p = (char*)pkg_malloc(8*sizeof(char));
if(p==NULL)
{
LM_ERR("cannot allocate pkg memory\n");
exit;
}
strcpy(p, "kamailio");
LM_DBG("string value at %p is [%s]\n", p, p);
pkg_free(p);
...
Realloc a previously allocated memory chunk. It copies the content of the old memory chunk to the new one. If the space after the old chunk is free and large enough to scale to the new size, the Kamailio memory manager will set the size of the old chunk to the new size, marking properly the memory zone, in this way, the copy operation is skipped.
The first parameter is the pointer to the memory space that needs to be re-sized. The second parameter is the new size in bytes. The function return the pointer to the new memory space, or NULL if an error occurred. Beware that the returned pointer may be different than the old pointer.
Example 4.6. Example of usage
...
#include "mem/mem.h"
...
char *p;
p = (char*)pkg_malloc(8*sizeof(char));
if(p==NULL)
{
LM_ERR("cannot allocate pkg memory\n");
exit;
}
strcpy(p, "kamailio");
LM_DBG("string value at %p is [%s]\n", p, p);
p = (char*)pkg_realloc(p, 16*sizeof(char));
if(p==NULL)
{
LM_ERR("cannot re-allocate pkg memory\n");
exit;
}
strcat(p, " server");
LM_DBG("string value at %p is [%s]\n", p, p);
pkg_free(p);
...
The data stored in shared memory is visible in all Kamailio modules. It is the space where user location records are stored, the TM structures for stateful processing, routing rules for the dispatcher or the lcr module, and many more.
The shared memory is initialized after the config file is parsed, because it need to know the user and group Kamailio is running under, for the case when the memory manger uses SysV operations.
To use shared memory functions in your C code you need to include the file: mem/shm_mem.h. When accessing shared memory data, you need to make sure that you don't have a race between different Kamailio processes, for example protect the access via a lock.
Allocates space in shared memory.
The parameter specifies the size in bytes of the desired shared memory space. It returns the pointer to shared memory in case of success, or NULL if an error occurred.
Example 4.8. Example of usage
...
#include "mem/shm_mem.h"
...
char *p;
p = (char*)shm_malloc(8*sizeof(char));
if(p==NULL)
{
LM_ERR("cannot allocate shm memory\n");
exit;
}
...
Free a shared memory space previously allocated with shm_share(...).
The parameter is the pointer to the shared memory space to be freed.
Example 4.10. Example of usage
...
#include "mem/shm_mem.h"
...
char *p;
p = (char*)shm_malloc(8*sizeof(char));
if(p==NULL)
{
LM_ERR("cannot allocate shm memory\n");
exit;
}
strcpy(p, "kamailio");
LM_DBG("string value at %p is [%s]\n", p, p);
shm_free(p);
...
Realloc a previously allocated shared memory chunk. It copies the content of the old memory chunk to the new one.
The first parameter is the pointer to the memory space that needs to be re-sized. The second parameter is the new size in bytes. The function return the pointer to the new memory space, or NULL if an error occurred. Beware that the returned pointer may be different than the old pointer.
Example 4.12. Example of usage
...
#include "mem/shm_mem.h"
...
char *p;
p = (char*)shm_malloc(8*sizeof(char));
if(p==NULL)
{
LM_ERR("cannot allocate shm memory\n");
exit;
}
strcpy(p, "kamailio");
LM_DBG("string value at %p is [%s]\n", p, p);
p = (char*)shm_realloc(p, 16*sizeof(char));
if(p==NULL)
{
LM_ERR("cannot re-allocate shm memory\n");
exit;
}
strcat(p, " server");
LM_DBG("string value at %p is [%s]\n", p, p);
shm_free(p);
...
There are two cases of memory problems:
memory leak - allocating memory at runtime and don't free it when no longer needing. It results in out of memory messages. Note that such messages might be because of a too small size of the memory for the traffic, data or number of subscribers that Kamailio has to handle -- you can increase shared memory using -m command line option and private memory using -M command line option.
memory overwriting - writing more than was allocated for that structure. It results in an segmentation fault, crashing Kamailio.
Kamailio has an internal debugger for memory - it is able to show the chunks allocated in private or shared memory and the file and line from where it was allocated. In debugging mode it prints all calls for allocations and freeing memory.
To enable the memory debugger you have to recompile Kamailio with MEMDBG=1 option to make tool.
Example 4.13. Building with memory debugging
... make cfg FLAVOUR=kamailio MEMDBG=1 ... make all ...
Once compiled and installed with memory debugging you have to set memlog parameter to a value lower than debug in configuration file. You can start Kamailio and try to reproduce the errors again. Once memory leak errors are printed you can either send a RPC command to the process that printed the messages or stop Kamailio. You get in the syslog file the status of the memory. If you see memory allocation done from the same place in the sources, many times, at runtime, it is a memory leak. If not, increase the memory size to fit your load needs and run again -- if you don't get the memory leak errors it was the case of insufficient memory allocated for Kamailio.
For sending the RPC command, you have to load ctl and cfg_rpc modules, then use sercmd tool:
Example 4.14. Dumping memory usage
... sercmd cfg.set_now_int core mem_dump_pkg [pid] ... sercmd cfg.set_now_int core mem_dump_shm [pid] ...
Monitoring used memory can be done also via RPC commands:
Example 4.15. Memory monitoring
...
sercmd> core.shmmem
{
total: 33554432
free: 30817888
used: 2512248
real_used: 2736544
max_used: 2736544
fragments: 1
}
...
sercmd> pkg.stats
{
entry: 0
pid: 60090
rank: 0
used: 217280
free: 3674296
real_used: 520008
}
{
entry: 1
pid: 60091
rank: 1
used: 225160
free: 3666320
real_used: 527984
}
...
It is possible to walk through the list of PKG fragments with gdb. For example, printing used fragment in the range 2000 to 10000:
...
set $i=0
set $a = mem_block->first_frag
while($i<10000)
if($i>2000)
if($a->u.is_free==0)
p *$a
end
end
set $a = ((struct qm_frag*)((char*)($a)+sizeof(struct qm_frag)+((struct qm_frag*)$a)->size+sizeof(struct qm_frag_end)))
set $i = $i + 1
end
...
For memory overwriting a core should be generated. If yes, you can investigate it with gdb.
... # gdb /path/to/kamailio corefile ...
From the backtrace you should get the file and line where the overwriting happened. In case a core is not generated, check the messages in the syslog. Look for BUG and error, for head or tail of a memory chunk being overwriting.
In this chapter we focus on most used data structures inside Kamailio sources. Most of them relate to SIP message structure. Other important data structures are explained in the chapters detailing specific components or functionalities -- for example, see Database API or Pseudo-variables chapters.
SIP is a text-based protocol, therefore lot of operations resume to text manipulation. Kamailio uses references in the SIP message body most of the time, doing it via an anchor pointer and the length. For that it uses the str structure.
The str structure is defined in file str.h.
Example 5.1. Definition
...
struct _str{
char* s; /* pointer to the beginning of string (char array) */
int len; /* string length */
};
typedef struct _str str;
...
Example 5.2. Example of usage
...
#include "str.h"
...
str s;
s.s = "kamailio";
s.len = strlen(s.s);
LM_DBG("the string is [%.*s]\n", s.len, s.s);
...
This is the structure holding a parsed SIP URI. You can fill it by calling parse_uri(...) function.
The structure is defined in file parser/msg_parser.h.
Example 5.3. Definition
...
struct sip_uri {
str user; /* Username */
str passwd; /* Password */
str host; /* Host name */
str port; /* Port number */
str params; /* URI Parameters */
str headers; /* URI Headers */
unsigned short port_no; /* Port number r*/
unsigned short proto; /* Transport protocol */
uri_type type; /* URI scheme */
/* parameters */
str transport; /* transport parameter */
str ttl; /* ttl parameter */
str user_param; /* user parameter */
str maddr; /* maddr parameter */
str method; /* method parameter */
str lr; /* lr parameter */
str r2; /* specific rr parameter */
/* values */
str transport_val; /* value of transport parameter */
str ttl_val; /* value of ttl parameter */
str user_param_val; /* value of user parameter */
str maddr_val; /* value of maddr parameter */
str method_val; /* value of method parameter */
str lr_val; /* value of lr parameter */
str r2_val; /* value of r2 parameter */
};
...
Members of the structure corresponds to a part of a SIP URI. To get details about the format of SIP URI read RFC3261. Example of SIP URI:
sip:alice@sipserver.org:5060;transport=tcp
This is the main structure related to a SIP message. When a SIP message is received from the network, it is parsed in such structure. The pointer to this structure is given as parameter to all functions exported by modules to be used in the configuration file.
The structure is defined in file parser/msg_parser.h.
Example 5.4. Definition
...
struct sip_msg {
unsigned int id; /* message id, unique/process*/
struct msg_start first_line; /* Message first line */
struct via_body* via1; /* The first via */
struct via_body* via2; /* The second via */
struct hdr_field* headers; /* All the parsed headers*/
struct hdr_field* last_header; /* Pointer to the last parsed header*/
hdr_flags_t parsed_flag; /* Already parsed header field types */
/* Via, To, CSeq, Call-Id, From, end of header*/
/* pointers to the first occurrences of these headers;
* everything is also saved in 'headers' (see above)
*/
/* shorcuts to known headers */
struct hdr_field* h_via1;
struct hdr_field* h_via2;
struct hdr_field* callid;
struct hdr_field* to;
struct hdr_field* cseq;
struct hdr_field* from;
struct hdr_field* contact;
struct hdr_field* maxforwards;
struct hdr_field* route;
struct hdr_field* record_route;
struct hdr_field* path;
struct hdr_field* content_type;
struct hdr_field* content_length;
struct hdr_field* authorization;
struct hdr_field* expires;
struct hdr_field* proxy_auth;
struct hdr_field* supported;
struct hdr_field* proxy_require;
struct hdr_field* unsupported;
struct hdr_field* allow;
struct hdr_field* event;
struct hdr_field* accept;
struct hdr_field* accept_language;
struct hdr_field* organization;
struct hdr_field* priority;
struct hdr_field* subject;
struct hdr_field* user_agent;
struct hdr_field* content_disposition;
struct hdr_field* accept_disposition;
struct hdr_field* diversion;
struct hdr_field* rpid;
struct hdr_field* refer_to;
struct hdr_field* session_expires;
struct hdr_field* min_se;
struct hdr_field* ppi;
struct hdr_field* pai;
struct hdr_field* privacy;
struct sdp_info* sdp; /* parsed SDP body */
char* eoh; /* pointer to the end of header (if found) or null */
char* unparsed; /* here we stopped parsing*/
struct receive_info rcv; /* source and dest ip, ports, proto a.s.o*/
char* buf; /* scratch pad, holds a unmodified message,
* via, etc. point into it */
unsigned int len; /* message len (orig) */
/* modifications */
str new_uri; /* changed first line uri, when you change this
* don't forget to set parsed_uri_ok to 0 */
str dst_uri; /* Destination URI, must be forwarded to this URI if len!=0 */
/* current uri */
int parsed_uri_ok; /* 1 if parsed_uri is valid, 0 if not, set it to 0
if you modify the uri (e.g change new_uri)*/
struct sip_uri parsed_uri; /* speed-up > keep here the parsed uri*/
/* the same for original uri */
int parsed_orig_ruri_ok;
struct sip_uri parsed_orig_ruri;
struct lump* add_rm; /* used for all the forwarded requests/replies */
struct lump* body_lumps; /* Lumps that update Content-Length */
struct lump_rpl *reply_lump; /* only for localy generated replies !!!*/
/* whatever whoever want to append to branch comes here */
char add_to_branch_s[MAX_BRANCH_PARAM_LEN];
int add_to_branch_len;
/* index to TM hash table; stored in core to avoid
* unnecessary calculations */
unsigned int hash_index;
/* flags used from script */
flag_t flags;
/* flags used by core - allows to set various flags on the message; may
* be used for simple inter-module communication or remembering
* processing state reached */
unsigned int msg_flags;
str set_global_address;
str set_global_port;
/* force sending on this socket */
struct socket_info* force_send_socket;
/* create a route HF out of this path vector */
str path_vec;
};
...
To fill such structure you can use function parse_msg(...) giving a buffer containing raw text of a SIP message. Most of the attributes in this structure point directly inside the SIP message buffer.
Example of a SIP message:
... REGISTER sip:sip.test.com SIP/2.0 Via: SIP/2.0/UDP 192.168.1.3:5061;branch=z9hG4bK-d663b80b Max-Forwards: 70 From: user <sip:u123@sip.test.com>;tag=ea8cef4b108a99bco1 To: user <sip:u123@sip.test.com> Call-ID: b96fead3-f03493d4@xyz CSeq: 3720 REGISTER Contact: user <sip:u123@192.168.1.3:5061>;expires=3600 User-Agent: Linksys/RT31P2-2.0.10(LIc) Content-Length: 0 Allow: ACK, BYE, CANCEL, INFO, INVITE, NOTIFY, OPTIONS, REFER Supported: x-sipura ...
The structure corresponds to a parsed representation of the first line in a SIP message. It is defined in file parser/parse_fline.h.
Example 5.5. Definition
...
struct msg_start {
int type; /* Type of the Message - Request or Response (Reply) */
int len; /* length including delimiter */
union {
struct {
str method; /* Method string */
str uri; /* Request URI as raw string */
str version; /* SIP version */
int method_value; /* Internal integer representation of SIP method */
} request;
struct {
str version; /* SIP version */
str status; /* Reply status */
str reason; /* Reply reason phrase */
unsigned int statuscode; /* Integer representation of reply status */
} reply;
}u;
};
...
To parse a buffer containing the first line of a SIP message you have to use the function parse_fline(...).
The structure holding a parsed SIP header. It is defined in file parser/hf.h.
Example 5.6. Definition
...
struct hdr_field {
hdr_types_t type; /* Header field type */
str name; /* Header field name */
str body; /* Header field body (may not include CRLF) */
int len; /* length from hdr start until EoHF (incl.CRLF) */
void* parsed; /* Parsed data structures */
struct hdr_field* next; /* Next header field in the list */
struct hdr_field* sibling; /* Next header of same type */
};
...
To parse specific headers in a SIP message you have to use the function parse_headers(...). The function takes as parameter a bitmask flag that can specify what headers you need to be parsed. For example, to parse the From and To headers:
parse_headers(msg, HDR_FROM_F|HDR_TO_F, 0);
To optimize the operations with headers, an integer value is assigned to most used headers. This value is stored in attribute type. Here is the list with the values for header type:
...
enum _hdr_types_t {
HDR_ERROR_T = -1 /* Error while parsing */,
HDR_OTHER_T = 0 /* Some other header field */,
HDR_VIA_T = 1 /* Via header field */,
HDR_VIA1_T = 1 /* First Via header field */,
HDR_VIA2_T = 2 /* only used as flag */,
HDR_TO_T /* To header field */,
HDR_FROM_T /* From header field */,
HDR_CSEQ_T /* CSeq header field */,
HDR_CALLID_T /* Call-Id header field */,
HDR_CONTACT_T /* Contact header field */,
HDR_MAXFORWARDS_T /* MaxForwards header field */,
HDR_ROUTE_T /* Route header field */,
HDR_RECORDROUTE_T /* Record-Route header field */,
HDR_PATH_T /* Path header fiels */,
HDR_CONTENTTYPE_T /* Content-Type header field */,
HDR_CONTENTLENGTH_T /* Content-Length header field */,
HDR_AUTHORIZATION_T /* Authorization header field */,
HDR_EXPIRES_T /* Expires header field */,
HDR_PROXYAUTH_T /* Proxy-Authorization hdr field */,
HDR_SUPPORTED_T /* Supported header field */,
HDR_PROXYREQUIRE_T /* Proxy-Require header field */,
HDR_UNSUPPORTED_T /* Unsupported header field */,
HDR_ALLOW_T /* Allow header field */,
HDR_EVENT_T /* Event header field */,
HDR_ACCEPT_T /* Accept header field */,
HDR_ACCEPTLANGUAGE_T /* Accept-Language header field */,
HDR_ORGANIZATION_T /* Organization header field */,
HDR_PRIORITY_T /* Priority header field */,
HDR_SUBJECT_T /* Subject header field */,
HDR_USERAGENT_T /* User-Agent header field */,
HDR_ACCEPTDISPOSITION_T /* Accept-Disposition hdr field */,
HDR_CONTENTDISPOSITION_T /* Content-Disposition hdr field */,
HDR_DIVERSION_T /* Diversion header field */,
HDR_RPID_T /* Remote-Party-ID header field */,
HDR_REFER_TO_T /* Refer-To header fiels */,
HDR_SESSION_EXPIRES_T /* Session-Expires header field */,
HDR_MIN_SE_T /* Min-SE header field */,
HDR_PPI_T /* P-Preferred-Identity header field */,
HDR_PAI_T /* P-Asserted-Identity header field */,
HDR_PRIVACY_T /* Privacy header field */,
HDR_RETRY_AFTER_T /* Retry-After header field */,
HDR_EOH_T /* Some other header field */
};
...
If the type of hdr_field structure is HDR_TO_T it is the parsed To header.
The attribute parsed may hold the parsed representation of the header body. For example, for Content-Lenght header it contains the content length value as integer.
The structure holds a parsed To header. Same structure is used for From header and the other headers that have same structure conform to IETF RFCs. The structure is defined in file parser/parse_to.h.
Example 5.7. Definition
...
struct to_body{
int error; /* Error code */
str body; /* The whole header field body */
str uri; /* URI withing the body of the header */
str display; /* Display Name */
str tag_value; /* Value of tag parameter*/
struct sip_uri parsed_uri; /* Parsed URI */
struct to_param *param_lst; /* Linked list of parameters */
struct to_param *last_param; /* Last parameter in the list */
};
...
To parse a To header you have to use function parse_to(...).
The structure holds a parsed Via header. It is defined in file parse_via.h.
Example 5.8. Definition
...
struct via_body {
int error; /* set if an error occurred during parsing */
str hdr; /* header name "Via" or "v" */
str name; /* protocol name */
str version; /* protocol version */
str transport; /* transport protocol */
str host; /* host part of Via header */
unsigned short proto; /* transport protocol as integer*/
unsigned short port; /* port number as integer */
str port_str; /* port number as string*/
str params; /* parameters */
str comment; /* comment */
unsigned int bsize; /* body size, not including hdr */
struct via_param* param_lst; /* list of parameters*/
struct via_param* last_param; /*last via parameter, internal use*/
/* shortcuts to "important" params*/
struct via_param* branch; /* branch parameter */
str tid; /* transaction id, part of branch */
struct via_param* received; /* received parameter */
struct via_param* rport; /* rport parameter */
struct via_param* i; /* i parameter */
struct via_param* alias; /* alias see draft-ietf-sip-connect-reuse-00 */
struct via_param* maddr; /* maddr parameter */
struct via_body* next; /* pointer to next via body string if compact Via or null */
};
...
The str attributes in the structure are referenced to SIP message buffer. To parse a Via header you have to use the function parse_via(...).
Kamailio includes its own implementation of SIP parser. It is known as lazy or incremental parser. That means it parses until it founds the required elements or encounters ends of SIP message.
All parsing functions and data structures are in the files from the directory parser. The main file for SIP message parsing is parser/msg_parser.c with the corresponding header file parser/msg_parser.h.
It does not parse entirely the parts of the SIP message. For most of the SIP headers, it identifies the name and body, it does not parse the content of header's body. It may happen that a header is malformed and Kamailio does not report any error as there was no request to parse that header body. However, most used headers are parsed entirely by default. Such headers are top most Via, To, CSeq, Content-Lenght.
The parser does not duplicate the values, it makes references inside the SIP message buffer it parses. For the parsed structures it allocates private memory. It keeps the state of parsing, meaning that it has an anchor to the beginning of unparsed part of the SIP message and stores a bitmask of flags with parsed known headers. If the function to parse a special header is called twice, the second time will return immediately as it finds in the bitmask that the header was already parsed.
This chapter in not intended to present all parsing functions, you have to check the files in the directory parser. There is kind of naming convention, so if you need the function to parse the header XYZ, look for the files parser/parse_XYZ.{c,h}. If you don't find it, second try is to use ctags to locate a parse_XYZ(...) function. If no luck, then ask on Kamailio development mailing list devel@lists.kamailio.org. Final solution in case on negative answer is to implement it yourself. For example, CSeq header parser is in parser/parse_cseq.{c,h}.
The next sections will present the parsing functions that give access to the most important parts of a SIP message.
Example 6.2. Example of URI parser usage
...
char *uri;
struct sip_uri parsed_uri;
uri = "sip:test@mydomain.com";
if(parse_uri(uri, strlen(uri), &parsed_uri)!=0)
{
LM_ERR("invalid uri [%s]\n", uri);
} else {
LM_DBG("uri user [%.*s], uri domain [%.*s]\n",
parsed_uri.user.len, parsed_uri.user.s,
parsed_uri.host.len, parsed_uri.host.s);
}
...
A developer does not interfere too much with this function as it is called automatically by Kamailio when a SIP message is received from the network.
You can use it if you load the content of SIP message from a file or database, or you received on different channels, up to your extension implementation. You should be aware that it is not enough to call this function and then run the actions from the configuration file. There are some attributes in the structure sip_msg that are specific to the environment: received socket, source IP and port, ...
Return 0 if parsing was OK, >0 if error occurred.
Example 6.4. Example of usage
...
str msg_buf;
struct sip_msg msg;
...
msg_buf.s = "INVITE sip:user@sipserver.com SIP/2.0\r\nVia: ...";
msg_buf.len = strlen(msg_buf.s);
if (parse_msg(buf,len, &msg)!=0) {
LM_ERR("parse_msg failed\n");
return -1;
}
if(msg.first_line.type==SIP_REQUEST)
LM_DBG("SIP method is [%.*s]\n", msg.first_line.u.request.method.len,
msg.first_line.u.request.method.s);
...
Parse the SIP message until the headers specified by parameter flags flags are found. The parameter next can be used when a header can occur many times in a SIP message, to continue parsing until a new header of that type is found.
The values that can be used for flags are defined in parser/hf.h.
When searching to get a specific header, all the headers encountered during parsing are hooked in the structure sip_msg.
Return 0 if parsing was sucessful, >0 in case of error.
Example 6.6. Example of usage
...
if(parse_headers(msg, HDR_CALLID_F, 0)!=0)
{
LM_ERR("error parsing CallID header\n");
return -1;
}
...
Parse a buffer that contains the body of a To header. The function is defined in parser/parse_to.h.
Return 0 in case of success, >0 in case of error.
The next example shows the parse_from(...) function that makes use of parse_to(...) to parse the body of header From. The function is located in file parser/parse_from.c.
The structure filled at parsing is hooked in the structure sip_msg, inside the attribute from, which is the shortcut to the header From.
Example 6.8. Example of usage
...
int parse_from_header( struct sip_msg *msg)
{
struct to_body* from_b;
if ( !msg->from && ( parse_headers(msg,HDR_FROM_F,0)==-1 || !msg->from)) {
LM_ERR("bad msg or missing FROM header\n");
goto error;
}
/* maybe the header is already parsed! */
if (msg->from->parsed)
return 0;
/* first, get some memory */
from_b = pkg_malloc(sizeof(struct to_body));
if (from_b == 0) {
LM_ERR("out of pkg_memory\n");
goto error;
}
/* now parse it!! */
memset(from_b, 0, sizeof(struct to_body));
parse_to(msg->from->body.s,msg->from->body.s+msg->from->body.len+1,from_b);
if (from_b->error == PARSE_ERROR) {
LM_ERR("bad from header\n");
pkg_free(from_b);
set_err_info(OSER_EC_PARSER, OSER_EL_MEDIUM, "error parsing From");
set_err_reply(400, "bad From header");
goto error;
}
msg->from->parsed = from_b;
return 0;
error:
return -1;
}
...
Next example shows how to get the content of SIP message body in a 'str' variable.
Example 6.9. Example of usage
...
int get_msg_body(struct sip_msg *msg, str *body)
{
/* 'msg' is a pointer to a valid struct sip_msg */
/* get message body
- after that whole SIP MESSAGE is parsed
- calls internally parse_headers(msg, HDR_EOH_F, 0)
*/
body->s = get_body( msg );
if (body->s==0)
{
LM_ERR("cannot extract body from msg\n");
return -1;
}
body->len = msg->len - (body->s - msg->buf);
/* content-length (if present) must be already parsed */
if (!msg->content_length)
{
LM_ERR("no Content-Length header found!\n");
return -1;
}
if(body->len != get_content_length( msg ))
LM_WARN("Content length header value different than body size\n");
return 0;
}
...
You can see in the next example how to access the body of header Call-ID.
Example 6.10. Example of usage
...
void print_callid_header(struct sip_msg *msg)
{
if(msg==NULL)
return;
if(parse_headers(msg, HDR_CALLID_F, 0)!=0)
{
LM_ERR("error parsing CallID header\n");
return;
}
if(msg->callid==NULL || msg->callid->body.s==NULL)
{
LM_ER("NULL call-id header\n");
return;
}
LM_INFO("Call-ID: %.*s\n", msg->callid->body.len, msg->callid->body.s);
}
...
The section gives the guidelines to add a new function for parsing a header.
add source and header files in directory parser naming them parse_hdrname.{c,h}.
if the header is used very often, consider doing speed optimization by allocating a header type and flag. That will allow to identify the header via integer comparison after the header was parsed and added in headers list in the structure sip_msg.
make sure you add the code to properly clean up the header structure when the structure sip_msg is freed.
make sure that the tm module properly clones the header or it resets the pointers to the header when copying the structure sip_msg in shared memory.
As a developer, the interaction with the transport layer is lower and lower. It is already implemented the support for UDP, TCP, TLS and SCTP. From the modules, you can use the API exported by sl and tm modules to send stateless replies, or to send stateful requests/replies. Sending stateless requests can be done with the functions from core, exported in file forward.h.
The core takes care of receiving the messages from the network, the basic validation for them, preparing the environment for a higher level processing of SIP messages. When developing new extensions, you don't have to care about reading/writing from/to network.
TLS implementation is a module, residing inside modules/tls. It reuses the TCP layer from the core for the management of the connection, while the code in modules/tls takes care of TLS negotiation and encryption.
If you want to investigate the implementation of transport layers, you can start with:
udp_*.{c,h} for UDP
tcp_*.{c,h} for TCP
modules/tls/*.{c,h} for TLS
sctp_*.{c,h} for SCTP
Kamailio follows the requirements specified in RFC3263 for server and service location. That includes support for NAPTR and SRV records as well.
To investigate the implementation related to DNS, start with files resolve.{c,h}.
There is an internal DNS cache which is necessary for doing DNS-based load balancing and failover. It can be disable via core parameters in the configuration file.
flex and bison are used to parse the configuration file and build the actions tree that are executed at run time for each SIP message. Bison is the GNU implementation compatible with Yacc (Yet Another Compiler Compiler), but also Yacc or Byacc can be used instead of it.
Extending the configuration file can be done by adding a new core parameter or a new core functions. Apart of these, one can add new routing blocks, keywords or init and runtime instructions.
Starting with release series 3.0, configuration file language has support for preprocessor directives. They provide an easy way to define tokens to values or enable/disable parts of configuration file.
The config file include two main categories of statements:
init statements - this category includes setting the global parameters, loading modules and setting module parameters. These statements are executed only one time, at startup.
runtime statements - this category includes the actions executed many times, after Kamailio initialization. These statements are grouped in route blocks, there being different route types that get executed for certain events.
route - is executed when a SIP request is received
onreply_route - is executed when a SIP reply is received
error_route - is executed when some errors (mainly related to message parsing) are encountered
failure_route - is executed when a negative reply was received for a transaction that armed the handler for the failure event.
branch_route - is executed for each destination branch of the transaction that armed the handler for it.
In the next section we will present how to add a core parameter and add a routing action -- core function. You need to have knowledge of flex and bison.
Some of the core parameters correspond to global variables in Kamailio sources. Others induce actions to be taken during statup.
Let's follow step by step the definition and usage of the core parameter log_name. It is a string parameter that specifies the value to be printed as application name in syslog messages.
First is the declaration of the variable in the C code. The log_name is defined in main.c and initialized to 0 (when set to o, it is printed the Kamailio name (including path) in the syslog).
... char *log_name = 0; ...
Next is to define the token in the flex file: cfg.lex.
... LOGNAME log_name ...
The association of a token ID and extending the grammar of the configuration file is done in the bison file: cfg.y.
...
%token LOGNAME
...
assign_stm: ...
| LOGNAME EQUAL STRING { log_name=$3; }
| LOGNAME EQUAL error { yyerror("string value expected"); }
...
The grammar was extended with a new assign statement, that allows to write in the configuration file an expression like:
... log_name = "kamailio123" ...
When having a line like above one in the configuration file, the variable log_name in C code will be initialized to the string in the right side of the equal operator.
To introduce new functions in Kamailio core that are exported to the configuration file the grammar have to be extended (bison and flex files), the interpreter must be enhanced to be able to run the new actions.
Behind each core function resides an action structure. This data type is defined in route_struct.h:
...
typedef struct {
action_param_type type;
union {
long number;
char* string;
struct _str str;
void* data;
avp_spec_t* attr;
select_t* select;
} u;
} action_u_t;
/* maximum internal array/params
* for module function calls val[0] and val[1] store a pointer to the
* function and the number of params, the rest are the function params
*/
#define MAX_ACTIONS (2+6)
struct action{
int cline;
char *cfile;
enum action_type type; /* forward, drop, log, send ...*/
int count;
struct action* next;
action_u_t val[MAX_ACTIONS];
};
...
Each action is identified by a type. The types of actions are defined in same header file. For example, the strip(...) function has the type STRIP_T, the functions exported by modules have the type MODULE_T.
To each action may be given a set of parameters, so called action elements. In case of functions exported by modules, the first element is the pointer to the function, next are the parameters given to that function in configuration file.
For debugging and error detection, the action keeps the line number in configuration file where it is used.
Next we discuss how setflag(...) config function was implemented.
Define the token in flex file: cfg.lex.
... SETFLAG "setflag" ...
Assign a token ID and extend the bison grammar.
...
%token SETFLAG
...
cmd: ...
| SETFLAG LPAREN NUMBER RPAREN {
if (check_flag($3)==-1)
yyerror("bad flag value");
$$=mk_action(SETFLAG_T, 1, NUMBER_ST,
(void*)$3);
set_cfg_pos($$);
}
| SETFLAG LPAREN flag_name RPAREN {
i_tmp=get_flag_no($3, strlen($3));
if (i_tmp<0) yyerror("flag not declared");
$$=mk_action(SETFLAG_T, 1, NUMBER_ST,
(void*)(long)i_tmp);
set_cfg_pos($$);
}
| SETFLAG error { $$=0; yyerror("missing '(' or ')'?"); }
...
First grammar specification says that setflag(...) can have one parameter of type number. The other rule for grammar is to detect error cases.
First step is to add a new action type in route_struct.h.
Then add a new case in the switch of action types, file action.c, function
...
case SETFLAG_T:
if (a->val[0].type!=NUMBER_ST) {
LOG(L_CRIT, "BUG: do_action: bad setflag() type %d\n",
a->val[0].type );
ret=E_BUG;
goto error;
}
if (!flag_in_range( a->val[0].u.number )) {
ret=E_CFG;
goto error;
}
setflag( msg, a->val[0].u.number );
ret=1;
break;
...
The C function setflag(...) is defined and implemented in flags.{c,h}. It simply sets the bit in flags attribute of sip_msg at the position given by the parameter.
...
int setflag( struct sip_msg* msg, flag_t flag ) {
msg->flags |= 1 << flag;
return 1;
}
...
We are not done yet. Kamailio does a checking of the actions tree after all configuration file was loaded. It does sanity checks and optimization for run time. For our case, it does a double-check that the parameter is a number and it is in the range of 0...31 to fit in the bits size of an integer value. See function fix_actions(...) in route.c.
Next example is given just to show how such fixup can look like, it is no longer used for flag operations functions.
...
case SETFLAG_T:
case RESETFLAG_T:
case ISFLAGSET_T:
if (t->elem[0].type!=NUMBER_ST) {
LM_CRIT("bad xxxflag() type %d\n", t->elem[0].type );
ret=E_BUG;
goto error;
}
if (!flag_in_range( t->elem[0].u.number )) {
ret=E_CFG;
goto error;
}
break;
...
Last thing you have to add is to complete the function print(action(...) with a new case for your action that will be used to print the actions tree -- for debugging purposes. See it in file route_struct.c.
...
case SETFLAG_T:
LM_DBG("setflag(");
break;
...
From now on, you can use in your configuration file the function setflag(_number_).
Don't forget to add documentation in Kamailio Core Cookbook.
Internally, Kamailio uses a reduced set of SQL operations to access the records on the storage system. This allowed to write DB driver modules for non-SQL storage systems, such as db_text -- a tiny DB engine using text files.
Therefore, the interface provides data types and functions that are independent of underlying DB storage. A DB driver module has to implement the functions specified by the interface and provide a function named db_bind_api(...) to link to the interface functions.
Starting with version 3.0.0, Kamailio has two variants of database APIs, stored as internal libraries, named srdb1 and srdb2. Most of Kamailio modules are using srdb1, thus for this document the focus will be on how to use this option.
The DB1 interface is implemented in the lib/srdb1 directory. To use it, one has to include the file lib/srdb1/db.h.
It is the structure that gets filled when binding to a DB driver module. It links to the interface functions implemented in the module.
Example 9.1. Definition
...
typedef struct db_func {
unsigned int cap; /* Capability vector of the database transport */
db_use_table_f use_table; /* Specify table name */
db_init_f init; /* Initialize database connection */
db_close_f close; /* Close database connection */
db_query_f query; /* query a table */
db_fetch_result_f fetch_result; /* fetch result */
db_raw_query_f raw_query; /* Raw query - SQL */
db_free_result_f free_result; /* Free a query result */
db_insert_f insert; /* Insert into table */
db_delete_f delete; /* Delete from table */
db_update_f update; /* Update table */
db_replace_f replace; /* Replace row in a table */
db_last_inserted_id_f last_inserted_id; /* Retrieve the last inserted ID
in a table */
db_insert_update_f insert_update; /* Insert into table, update on duplicate key */
db_insert_delayed_f insert_delayed; /* Insert delayed into table */
db_affected_rows_f affected_rows; /* Numer of affected rows for last query */
} db_func_t;
...
The attribute cap is a bitmask of implemented functions, making easy to detect the capabilities of the DB driver module. A module using the DB API should check at startup that the DB driver configured to be used has the required capabilities. For example, msilo module need select, delete and insert capabilities. The flags for capabilities are enumerated in the next figure (located in lib/srdb1/db_cap.h).
...
typedef enum db_cap {
DB_CAP_QUERY = 1 << 0, /* driver can perform queries */
DB_CAP_RAW_QUERY = 1 << 1, /* driver can perform raw queries */
DB_CAP_INSERT = 1 << 2, /* driver can insert data */
DB_CAP_DELETE = 1 << 3, /* driver can delete data */
DB_CAP_UPDATE = 1 << 4, /* driver can update data */
DB_CAP_REPLACE = 1 << 5, /* driver can replace (also known as INSERT OR UPDATE) data */
DB_CAP_FETCH = 1 << 6, /* driver supports fetch result queries */
DB_CAP_LAST_INSERTED_ID = 1 << 7, /* driver can return the ID of the last insert operation */
DB_CAP_INSERT_UPDATE = 1 << 8, /* driver can insert data into database, update on duplicate */
DB_CAP_INSERT_DELAYED = 1 << 9, /* driver can do insert delayed */
DB_CAP_AFFECTED_ROWS = 1 << 10 /* driver can return number of rows affected by last query */
} db_cap_t;
...
Parse the DB URL and open a new connection to database.
Parameters:
_url - database URL. Its format depends on DB driver. For an SQL server like MySQL has to be: mysql://username:password@server:port/database. For db_text has to be: text:///path/to/db/directory.
The function returns pointer to db1_con_t* representing the connection structure or NULL in case of error.
The function closes previously open connection and frees all previously allocated memory. The function db_close must be the very last function called.
Parameters:
_h - db1_con_t structure representing the database connection.
The function returns nothing.
Specify table name that will be used for subsequent operations (insert, delete, update, query).
Parameters:
_h - database connection handle.
_t - table name.
The function 0 if everything is OK, otherwise returns value negative value.
Query table for specified rows. This function implements the SELECT SQL directive.
Example 9.5. Function type
... typedef int (*db_query_f) (const db1_con_t* _h, const db_key_t* _k, const db_op_t* _op, const db_val_t* _v, const db_key_t* _c, const int _n, const int _nc, const db_key_t _o, db1_res_t** _r); ...
Parameters:
_h - database connection handle.
_k - array of column names that will be compared and their values must match.
_op - array of operators to be used with key-value pairs.
_v - array of values, columns specified in _k parameter must match these values.
_c - array of column names that you are interested in.
_n - number of key-value pairs to match in _k and _v parameters.
_nc - number of columns in _c parameter.
_o - order by statement for query.
_r - address of variable where pointer to the result will be stored.
The function 0 if everything is OK, otherwise returns value negative value.
Note: If _k and _v parameters are NULL and _n is zero, you will get the whole table. If _c is NULL and _nc is zero, you will get all table columns in the result. Parameter _r will point to a dynamically allocated structure, it is neccessary to call db_free_result function once you are finished with the result. If _op is 0, equal (=) will be used for all key-value pairs comparisons. Strings in the result are not duplicated, they will be discarded if you call. Make a copy of db_free_result if you need to keep it after db_free_result. You must call db_free_result before you can call db_query again!
Fetch a number of rows from a result.
Example 9.6. Function type
... typedef int (*db_fetch_result_f) (const db1_con_t* _h, db1_res_t** _r, const int _n); ...
Parameters:
_h - database connection handle.
_r - structure for the result.
_n - the number of rows that should be fetched.
The function 0 if everything is OK, otherwise returns value negative value.
This function can be used to do database specific queries. Please use this function only if needed, as this creates portability issues for the different databases. Also keep in mind that you need to escape all external data sources that you use. You could use the escape_common and unescape_common functions in the core for this task.
Example 9.7. Function type
... typedef int (*db_raw_query_f) (const db1_con_t* _h, const str* _s, db1_res_t** _r); ...
Parameters:
_h - database connection handle.
_s - the SQL query.
_r - structure for the result.
The function 0 if everything is OK, otherwise returns value negative value.
Free a result allocated by db_query.
Parameters:
_h - database connection handle.
_r - pointer to db1_res_t structure to destroy.
The function 0 if everything is OK, otherwise returns value negative value.
Insert a row into the specified table.
Example 9.9. Function type
... typedef int (*db_insert_f) (const db1_con_t* _h, const db_key_t* _k, const db_val_t* _v, const int _n); ...
Parameters:
_h - database connection handle.
_k - array of keys (column names).
_v - array of values for keys specified in _k parameter.
_n - number of keys-value pairs int _k and _v parameters.
The function 0 if everything is OK, otherwise returns value negative value.
Delete a row from the specified table.
Example 9.10. Function type
... typedef int (*db_delete_f) (const db1_con_t* _h, const db_key_t* _k, const db_op_t* _o, const db_val_t* _v, const int _n); ...
Parameters:
_h - database connection handle.
_k - array of keys (column names) that will be matched.
_o - array of operators to be used with key-value pairs.
_v - array of values that the row must match to be deleted.
_n - number of keys-value pairs int _k and _v parameters.
The function 0 if everything is OK, otherwise returns value negative value.
Update some rows in the specified table.
Example 9.11. Function type
... typedef int (*db_update_f) (const db1_con_t* _h, const db_key_t* _k, const db_op_t* _o, const db_val_t* _v, const db_key_t* _uk, const db_val_t* _uv, const int _n, const int _un); ...
Parameters:
_h - database connection handle.
_k - array of keys (column names) that will be matched.
_o - array of operators to be used with key-value pairs.
_v - array of values that the row must match to be modified.
_uk - array of keys (column names) that will be modified.
_uv - new values for keys specified in _k parameter.
_n - number of key-value pairs in _v parameters.
_un - number of key-value pairs in _uv parameters.
The function 0 if everything is OK, otherwise returns value negative value.
Insert a row and replace if one already exists.
Example 9.12. Function type
... typedef int (*db_replace_f) (const db1_con_t* handle, const db_key_t* keys, const db_val_t* vals, const int n); ...
Parameters:
_h - database connection handle.
_k - array of keys (column names).
_v - array of values for keys specified in _k parameter.
_n - number of keys-value pairs int _k and _v parameters.
The function 0 if everything is OK, otherwise returns value negative value.
Retrieve the last inserted ID in a table.
Parameters:
_h - structure representing database connection
The function returns the ID as integer or returns 0 if the previous statement does not use an AUTO_INCREMENT value.
Insert a row into specified table, update on duplicate key.
Example 9.14. Function type
... typedef int (*db_insert_update_f) (const db1_con_t* _h, const db_key_t* _k, const db_val_t* _v, const int _n); ...
Parameters:
_h - database connection handle.
_k - array of keys (column names).
_v - array of values for keys specified in _k parameter.
_n - number of keys-value pairs int _k and _v parameters.
The function 0 if everything is OK, otherwise returns value negative value.
Insert delayed a row into specified table - don't wait for confirmation from database server.
Example 9.15. Function type
... typedef int (*db_insert_delayed_f) (const db1_con_t* _h, const db_key_t* _k, const db_val_t* _v, const int _n); ...
Parameters:
_h - database connection handle.
_k - array of keys (column names).
_v - array of values for keys specified in _k parameter.
_n - number of keys-value pairs int _k and _v parameters.
The function 0 if everything is OK, otherwise returns value negative value.
Retrieve the number of affected rows by last operation done to database.
Parameters:
_h - structure representing database connection
The function returns the number of affected rows by previous DB operation.
This type represents a database key (column). Every time you need to specify a key value, this type should be used.
This type represents an expression operator uses for SQL queries.
Predefined operators are:
Example 9.19. DB Expression Operators
... typedef const char* db_op_t; /** operator less than */ #define OP_LT "<" /** operator greater than */ #define OP_GT ">" /** operator equal */ #define OP_EQ "=" /** operator less than equal */ #define OP_LEQ "<=" /** operator greater than equal */ #define OP_GEQ ">=" /** operator negation */ #define OP_NEQ "!=" ...
Each cell in a database table can be of a different type. To distinguish among these types, the db_type_t enumeration is used. Every value of the enumeration represents one datatype that is recognized by the database API.
Example 9.20. Definition
...
typedef enum {
DB1_INT, /* represents an 32 bit integer number */
DB1_BIGINT, /* represents an 64 bit integer number */
DB1_DOUBLE, /* represents a floating point number */
DB1_STRING, /* represents a zero terminated const char* */
DB1_STR, /* represents a string of 'str' type */
DB1_DATETIME, /* represents date and time */
DB1_BLOB, /* represents a large binary object */
DB1_BITMAP /* an one-dimensional array of 32 flags */
} db_type_t;
...
This structure represents a value in the database. Several datatypes are recognized and converted by the database API. These datatypes are automatically recognized, converted from internal database representation and stored in the variable of corresponding type. Modules that want to use this values needs to copy them to another memory location, because after the call to free_result there are not more available. If the structure holds a pointer to a string value that needs to be freed because the module allocated new memory for it then the free flag must be set to a non-zero value. A free flag of zero means that the string data must be freed internally by the database driver.
Example 9.21. Definition
...
typedef struct {
db_type_t type; /* Type of the value */
int nul; /* Means that the column in database has no value */
int free; /* Means that the value should be freed */
/** Column value structure that holds the actual data in a union. */
union {
int int_val; /* integer value */
long long ll_val; /* long long value */
double double_val; /* double value */
time_t time_val; /* unix time_t value */
const char* string_val; /* zero terminated string */
str str_val; /* str type string value */
str blob_val; /* binary object data */
unsigned int bitmap_val; /* Bitmap data type */
} val;
} db_val_t;
...
This structure represents a database connection, pointer to this structure are used as a connection handle from modules uses the db API.
Example 9.22. Definition
...
typedef struct {
const str* table; /* Default table that should be used */
unsigned long tail; /* Variable length tail, database module specific */
} db1_con_t;
...
Structure holding the result of a query table function. It represents one row in a database table. In other words, the row is an array of db_val_t variables, where each db_val_t variable represents exactly one cell in the table.
Example 9.23. Definition
...
typedef struct db_row {
db_val_t* values; /* Columns in the row */
int n; /* Number of columns in the row */
} db_row_t;
...
This type represents a result returned by db_query function (see below). The result can consist of zero or more rows (see db_row_t description).
Note: A variable of type db_res_t returned by db_query function uses dynamically allocated memory, don't forget to call db_free_result if you don't need the variable anymore. You will encounter memory leaks if you fail to do this! In addition to zero or more rows, each db_res_t object contains also an array of db_key_t objects. The objects represent keys (names of columns).
Example 9.24. Definition
...
typedef struct db1_res {
struct {
db_key_t* names; /* Column names */
db_type_t* types; /* Column types */
int n; /* Number of columns */
} col;
struct db_row* rows; /* Rows */
int n; /* Number of rows in current fetch */
int res_rows; /* Number of total rows in query */
int last_row; /* Last row */
} db1_res_t;
...
The DB API offers a set of macros to make easier to access the attributes in various data structures.
Macros for db_res_t:
RES_NAMES(res) - get the pointer to column names
RES_COL_N(res) - get the number of columns
RES_ROWS(res) - get the pointer to rows
RES_ROW_N(res) - get the number of rows
Macros for db_val_t:
ROW_VALUES(row) - get the pointer to values in the row
ROW_N(row) - get the number of values in the row
Macros for db_val_t:
VAL_TYPE(val) - get/set the type of a value
VAL_NULL(val) - get/set the NULL flag for a value
VAL_INT(val) - get/set the integer value
VAL_BIGINT(val) - get/set the big integer value
VAL_STRING(val) - get/set the null-terminated string value
VAL_STR(val) - get/set the str value
VAL_DOUBLE(val) - get/set the double value
VAL_TIME(val) - get/set the time value
VAL_BLOB(val) - get/set the blob value
A simple example of doing a select. The table is named test and has two columns.
...
create table test (
a int,
b varchar(64)
);
...
The C code:
...
#include "../../dprint.h"
#include "../../lib/srdb1/db.h"
db_func_t db_funcs; /* Database API functions */
db1_con_t* db_handle=0; /* Database connection handle */
int db_example(char *db_url)
{
str table;
str col_a;
str col_b;
int nr_keys=0;
db_key_t db_keys[1];
db_val_t db_vals[1];
db_key_t db_cols[1];
db1_res_t* db_res = NULL;
/* Bind the database module */
if (db_bind_mod(&db_url, &db_funcs))
{
LM_ERR("failed to bind database module\n");
return -1;
}
/* Check for SELECT capability */
if (!DB_CAPABILITY(db_funcs, DB_CAP_QUERY))
{
LM_ERR("Database modules does not "
"provide all functions needed here\n");
return -1;
}
/* Connect to DB */
db_handle = db_funcs.init(&db_url);
if (!db_handle)
{
LM_ERR("failed to connect database\n");
return -1;
}
/* Prepare the data for the query */
table.s = "test";
table.len = 4;
col_a.s = "a";
col_a.len = 1;
col_b.s = "b";
col_b.len = 1;
db_cols[0] = &col_b;
db_keys[0] = &col_a;
db_vals[nr_keys].type = DB_INT;
db_vals[nr_keys].nul = 0;
db_vals[nr_keys].val.int_val = 1;
nr_keys++;
/* execute the query */
/* -- select b from test where a=1 */
db_funcs.use_table(db_handle, &table);
if(db_funcs.query(db_handle, db_keys, NULL, db_vals, db_cols,
nr_keys /*no keys*/, 1 /*no cols*/, NULL, &db_res)!=0)
{
LM_ERR("failed to query database\n");
db_funcs.close(db_handle);
return -1;
}
if (RES_ROW_N(db_res)<=0 || RES_ROWS(db_res)[0].values[0].nul != 0)
{
LM_DBG("no value found\n");
if (db_res!=NULL && db_funcs.free_result(db_handle, db_res) < 0)
LM_DBG("failed to free the result\n");
db_funcs.close(db_handle);
return -1;
}
/* Print the first value */
if(RES_ROWS(db_res)[0].values[0].type == DB_STRING)
LM_DBG("first value found is [%s]\n",
(char*)RES_ROWS(db_res)[0].values[0].val.string_val);
else if(RES_ROWS(db_res)[0].values[0].type == DB_STR)
LM_DBG("first value found is [%.*s]\n",
RES_ROWS(db_res)[0].values[0].val.str_val.len,
(char*)RES_ROWS(db_res)[0].values[0].val.str_val.s);
else
LM_DBG("first value found has an unexpected type [%d]\n",
RES_ROWS(db_res)[0].values[0].type);
/* Free the result */
db_funcs.free_result(db_handle, db_res);
db_funcs.close(db_handle);
return 0;
}
...
Control interfaces are channels to communicate with Kamailio SIP server for administrative purposes. At this moment are two control interfaces:
MI - management interface - it is no longer the recommended control interface and it is planned to be obsoleted in the near future
RPC - remote procedure call - a more standardized option to execute commands. It is the recommended control interface.
RPC is designed as scanner-printer communication channel - RPC commands will scan the input for parameters as needed and will print back.
fifo - (ctl module) - the communication is done via FIFO file using a simple text-based, line oriented protocol.
datagram - (ctl module) - the communication is done via unix socket files or UDP sockets.
tcp - (ctl module) - the communication is done via unix socket files or TCP sockets.
xmlrpc - (xmlrpc module) - the communication is done via XMLRPC
RPC API is very well documented at: http://www.kamailio.org/docs/docbooks/3.2.x/rpc_api/rpc_api.html. We will show next just an example of implementing a RPC command: pkg.stats - dump usage statistics of PKG (private) memory, implemented in modules_k/kex.
Example 10.1. Example of RPC command - pkg.stats
...
/**
*
*/
static const char* rpc_pkg_stats_doc[2] = {
"Private memory (pkg) statistics per process",
0
};
/**
*
*/
int pkg_proc_get_pid_index(unsigned int pid)
{
int i;
for(i=0; i<_pkg_proc_stats_no; i++)
{
if(_pkg_proc_stats_list[i].pid == pid)
return i;
}
return -1;
}
/**
*
*/
static void rpc_pkg_stats(rpc_t* rpc, void* ctx)
{
int i;
int limit;
int cval;
str cname;
void* th;
int mode;
if(_pkg_proc_stats_list==NULL)
{
rpc->fault(ctx, 500, "Not initialized");
return;
}
i = 0;
mode = 0;
cval = 0;
limit = _pkg_proc_stats_no;
if (rpc->scan(ctx, "*S", &cname) == 1)
{
if(cname.len==3 && strncmp(cname.s, "pid", 3)==0)
mode = 1;
else if(cname.len==4 && strncmp(cname.s, "rank", 4)==0)
mode = 2;
else if(cname.len==5 && strncmp(cname.s, "index", 5)==0)
mode = 3;
else {
rpc->fault(ctx, 500, "Invalid filter type");
return;
}
if (rpc->scan(ctx, "d", &cval) < 1)
{
rpc->fault(ctx, 500, "One more parameter expected");
return;
}
if(mode==1)
{
i = pkg_proc_get_pid_index((unsigned int)cval);
if(i<0)
{
rpc->fault(ctx, 500, "No such pid");
return;
}
limit = i + 1;
} else if(mode==3) {
i=cval;
limit = i + 1;
}
}
for(; i<limit; i++)
{
/* add entry node */
if(mode!=2 || _pkg_proc_stats_list[i].rank==cval)
{
if (rpc->add(ctx, "{", &th) < 0)
{
rpc->fault(ctx, 500, "Internal error creating rpc");
return;
}
if(rpc->struct_add(th, "dddddd",
"entry", i,
"pid", _pkg_proc_stats_list[i].pid,
"rank", _pkg_proc_stats_list[i].rank,
"used", _pkg_proc_stats_list[i].used,
"free", _pkg_proc_stats_list[i].available,
"real_used", _pkg_proc_stats_list[i].real_used
)<0)
{
rpc->fault(ctx, 500, "Internal error creating rpc");
return;
}
}
}
}
/**
*
*/
rpc_export_t kex_pkg_rpc[] = {
{"pkg.stats", rpc_pkg_stats, rpc_pkg_stats_doc, 0},
{0, 0, 0, 0}
};
/**
*
*/
int pkg_proc_stats_init_rpc(void)
{
if (rpc_register_array(kex_pkg_rpc)!=0)
{
LM_ERR("failed to register RPC commands\n");
return -1;
}
return 0;
}
...
To add new RPC commands to control interface, you have to register them. One option, which is used here, is to build an array with the new commands and the help messages for each one and the use rpc_register_array(...) function. You have the register the commands in mod_init() function - in our example it is done via pkg_proc_stats_init(), which is a wrapper function called from mod_init().
pkg.stats commands has optional parameters, which can be used to specify the pid, internal rank or position in internal process table (index) of the application process for which to dump the private memory statistics. If there is no parameter given, the the statistics for all processes will be printed.
The command itself is implemented in C function rpc_pkg_stats(...). In the first part, it reads the parameters. You can see there the search for optional parameter is done by using '*' in the front of the type of parameter (str):
rpc->scan(ctx, "*S", &cname)
If this parameter is found, then there has to be another one, which this time is no longer optional.
rpc->scan(ctx, "d", &cval)
Once input is read, follows the printing of the result in RPC structures. When kex module is loaded, one can use pkg.stats command via sercmd tool like:
sercmd pkg.stats sercmd pkg.stats index 2 sercmd pkg.stats rank 4 sercmd pkg.stats pid 8492
The Management Interface is an abstract layer introduced to allow interaction between Kamailio and external applications like shell terminal or web applications. It is an old alternative to RPC control interface, which is going to be obsoleted in the future.
MI is built on a tree architecture - the input is parsed completely and stored as a tree in memory. The commands get access to the tree and build another tree with the response, which is then printed back to the transport layer.
In the past, there were two ways to interact with such applications: via FIFO file and via unix sockets.
MI came and introduced an abstractization between the transport and application levels. All MI commands are available for all available transports. At this moment the following transports are available:
fifo - (mi_fifo mofule) - the communication is done via FIFO file using a simple text-based, line oriented protocol.
xmlrpc - (mi_xmlrpc) - the communication is done via XMLRPC
datagram - (mi_datagram) - the communication is done via unix socket files or UDP sockets.
To implement a new command for MI you don't need to interact with the transports. MI will pass to your function a compiled version of the command, in the form of a tree. The functions walks through the tree, finds the input parameters, executes the actions accordingly, and returns a new MI tree with the response to the command.
The function you have to implement for a new MI command has a simple prototype.
... struct mi_root my_my_function(struct mi_root *tree, void *param); ...
Parameters:
tree - the tree with the input parameters sent via the transport layer. The struct mi_root is defined in mi/three.h.
... struct mi_node { str value; /* value of node (parameter) */ str name; /* name of node (parameter) */ struct mi_node *kids; /* children nodes */ struct mi_node *next; /* sibling nodes */ struct mi_node *last; /* last node */ struct mi_attr *attributes; /* the attributes of the node */ }; struct mi_root { unsigned int code; /* return code of the command */ str reason; /* reason code */ struct mi_handler *async_hdl; /* handler function for asynchronous replying */ struct mi_node node; /* head of the tree with parameters (nodes) */ }; ...param - parameter given when registering the command to MI.
Returns a tree containing the response to be send back for that command or NULL in case of error.
It is recommended to register new MI commands via Kamailio module interface - described later, in the chapted about module development.
The alternative is to use register_mi_cmd(...), defined in file mi/mi.h.
... typedef struct mi_root* (mi_cmd_f)(struct mi_root*, void *param); typedef int (mi_child_init_f)(void); int register_mi_cmd(mi_cmd_f f, char *name, void *param, mi_child_init_f in, unsigned int flags); ...
Parameters:
f - function to be called when the command is received from the transport layer
name - the name of the command
param - parameter to be given when function is executed
in - function to be executed at Kamailio initialization time
flags - set of flags describing properties of the command
... #define MI_ASYNC_RPL_FLAG (1<<0) // - the reply to command is asynchronous #define MI_NO_INPUT_FLAG (1<<1) // - the command does not get any input parameters ...
Returns 0 if the MI command was successfully registered, <0 in case of error.
We look at a MI command exported by dispatcher module. The command allow to set the state (active/inactive) for a destination address in the dispatching list (read documentation for dispatcher module).
The command expects 3 parameters:
state - the state to set to the destination address
group - the id of the group (destination set) the destination belongs to
address - the address of the destination to change the state for it
The function expects to find in the input tree, one flag (state), one number (group) and a string (the address). If not, an reply containing error message is sent back. If the parameters are ok and the destination is found, the state is changed accordingly and successful code and message is sent back, in not, an appropriate error code and message is sent back.
Code is shown below (in the sources look in file modules/dispatcher/dispatcher.c).
...
static struct mi_root* ds_mi_set(struct mi_root* cmd_tree, void* param)
{
str sp;
int ret;
unsigned int group, state;
struct mi_node* node;
node = cmd_tree->node.kids;
if(node == NULL)
return init_mi_tree(400, MI_MISSING_PARM_S, MI_MISSING_PARM_LEN);
sp = node->value;
if(sp.len<=0 || !sp.s)
{
LM_ERR("bad state value\n");
return init_mi_tree(500, "bad state value", 15);
}
state = 0;
if(sp.s[0]=='0' || sp.s[0]=='I' || sp.s[0]=='i') {
/* set inactive */
state |= DS_INACTIVE_DST;
if((sp.len>1) && (sp.s[1]=='P' || sp.s[1]=='p'))
state |= DS_PROBING_DST;
} else if(sp.s[0]=='1' || sp.s[0]=='A' || sp.s[0]=='a') {
/* set active */
if((sp.len>1) && (sp.s[1]=='P' || sp.s[1]=='p'))
state |= DS_PROBING_DST;
} else if(sp.s[0]=='2' || sp.s[0]=='D' || sp.s[0]=='d') {
/* set disabled */
state |= DS_DISABLED_DST;
} else if(sp.s[0]=='3' || sp.s[0]=='T' || sp.s[0]=='t') {
/* set trying */
state |= DS_TRYING_DST;
if((sp.len>1) && (sp.s[1]=='P' || sp.s[1]=='p'))
state |= DS_PROBING_DST;
} else {
LM_ERR("unknow state value\n");
return init_mi_tree(500, "unknown state value", 19);
}
node = node->next;
if(node == NULL)
return init_mi_tree(400, MI_MISSING_PARM_S, MI_MISSING_PARM_LEN);
sp = node->value;
if(sp.s == NULL)
{
return init_mi_tree(500, "group not found", 15);
}
if(str2int(&sp, &group))
{
LM_ERR("bad group value\n");
return init_mi_tree( 500, "bad group value", 16);
}
node= node->next;
if(node == NULL)
return init_mi_tree( 400, MI_MISSING_PARM_S, MI_MISSING_PARM_LEN);
sp = node->value;
if(sp.s == NULL)
{
return init_mi_tree(500,"address not found", 18 );
}
ret = ds_reinit_state(group, &sp, state);
if(ret!=0)
{
return init_mi_tree(404, "destination not found", 21);
}
return init_mi_tree( 200, MI_OK_S, MI_OK_LEN);
}
...
The structure of the command that has to be sent to transport layer depends on the implementation. Check the documentation of the modules implementing the MI transports.
For FIFO, the structure is line oriented, command being plain text.
... :_command_name_:_reply_fifo_file_ _parameters_ _empty_line_ ...
MI FIFO command structure:
_command_name_ - the name of the command
_reply_fifo_file_ - the FIFO file where to write the reply message
_parameters_ - values for parameters, one per line
_empty_line_ - an empty line to mark the end of the command
For the command described in the previous section, it can look like:
... :ds_set_state:kamailio_fifo_reply i 2 sip:10.10.10.10:5080 \n ...
Why this name? Yes, they are kind of variables, but a bit different:
some are read-only - most of them are read-only, because they are references inside the original SIP message and that does not change during config file execution (see Data Lump chapter.)
some are array - even if looks as simple variable name, assigning a value means to add one more in an array - the case for $avp(name).
So, they were named pseudo-variable. Initially they were introduced in xlog module having a simple mechanism behind. There is a marker character ($ in this case) to identify the start of pseudo-variable name from the rest of the text. To a pseudo-variable name was associated a function that returned a string value. That value was replacing the pseudo-variable name in the message printed to syslog.
Lately the concept was extended to include AVPs, to have writable pseudo-variables and to be possible to use them directly in the configuration file. Also, some of them can have dynamic name and index.
The framework for pseudo-variables is now easy to extend. They can be introduced as core pseudo-variables or exported by modules (this is preferred option). We will show such case further in the document.
The naming format for a pseudo-variable is described in the next example:
...
marker classname
marker '(' classname ')'
marker '(' classname '[' index ']' ')'
marker '(' classname ( '{' transformation '}' )+ ')'
marker '(' classname '[' index ']' ( '{' transformation '}' )+ ')'
marker classname '(' innername ')'
marker '(' classname '(' innername ')' ')'
marker '(' classname '(' innername ')' '[' index ']' ')'
marker '(' classname '(' innername ')' ( '{' transformation '}' )+ ')'
marker '(' classname '(' innername ')' '[' index ']' ( '{' transformation '}' )+ ')'
...
Meaning of the tokens:
marker - it is the char $
classname - a string specifying the class of pseudo-variables. A class can have on pseudo-variable, when the innername is missing. Lot of references to parts of SIP message are single PV class, e.g., $ru - request URI.
Classes with more than one pseudo-variable are AVPs ($avp(name)), references to headers ($hdr(name)), script vars ($var(name)) and several others.
innername - the name specifying the pseudo-variable in a class. It can be dynamic (specified by the value of another pseudo-variable), but depends on the pseudo-variable class, it is not valid for all classes.
index - index in the array, when the pseudo-variable can have multiple values at the same time. Such pseudo-variables are header references and AVPs. Also the index can have dynamic value, up to pseudo-variable class implementation.
transformation - kind of function that are applied to the value of the pseudo-variable. A dedicated chapter is included in this tutorial.
Some examples with pseudo-variable names:
...
$ru - reference to request URI
$(ru) - same as above - this format can be used when the class name cannot be delimited. It must
be used if the PV has index or transformations.
$avp(s:test) - the AVP with the string name 'test'
$(avp(test)[2]) - the third AVP with the string name 'test'
...
The prototypes and data structures for pseudo-variables are defined in pvar.h.
Is the structure returned by the get function associated to a pseudo-variable. It includes the flags that describe the value. It can have integer and string value, in most of the case, the string value is all the time set as PV used to be involved in string operations.
...
typedef struct _pv_value
{
str rs; /* string value */
int ri; /* integer value */
int flags; /* flags about the type of value */
} pv_value_t, *pv_value_p;
...
The type can be a combination of the following flags:
... #define PV_VAL_NONE 0 // no actual value -- it is so just at initialization #define PV_VAL_NULL 1 // the value must be considered NULL #define PV_VAL_EMPTY 2 // the value is an empty string (deprecated) #define PV_VAL_STR 4 // the value has the string attribute 'rs' set #define PV_VAL_INT 8 // the value has the integer attribute 'ri' set #define PV_TYPE_INT 16 // the value may have both string and integer attribute set, but type is integer #define PV_VAL_PKG 32 // the value was duplicated in pkg memory, free it accordingly at destroy time #define PV_VAL_SHM 64 // the value was duplicated in shm memory, free it accordingly at destroy time ...
The structure to store the specifications for innername. Can be integer or string (e.g., for AVPs). It can be a pointer to another pseudo-variable specifier or something else, up to implementation.
...
typedef struct _pv_name
{
int type; /* type of name */
union {
struct {
int type; /* type of int_str name - compatibility with AVPs */
int_str name; /* the value of the name */
} isname;
void *dname; /* PV value - dynamic name */
} u;
} pv_name_t, *pv_name_p;
...
Type can be:
... #define PV_NAME_INTSTR 0 // the name is constant, an integer or string #define PV_NAME_PVAR 1 // the name is dynamic, a pseudo-variable #define PV_NAME_OTHER 2 // the name is specific per implementation ...
Type for isname can be:
... 0 // the name is integer #define AVP_NAME_STR (1<<0) // 1 - the name is string ...
The structure holding index specifications.
...
typedef struct _pv_index
{
int type; /* type of PV index */
union {
int ival; /* integer value */
void *dval; /* PV value - dynamic index */
} u;
} pv_index_t, *pv_index_p;
...
Type can be:
...
#define PV_IDX_INT 0 // the index is integer value
#define PV_IDX_PVAR 1 // the index is dynamic, a pseudo-variable
#define PV_IDX_ALL 2 // the index specifies to return all values for that pseudo-variables
// - this is up to implementation of pseudo-variable class
...
The structure groups the name and the index to be easy to give them as parameter to the functions that requires them.
...
typedef struct _pv_param
{
pv_name_t pvn; /* PV name */
pv_index_t pvi; /* PV index */
} pv_param_t, *pv_param_p;
...
The structure that describes the pseudo-variable - the PV spec. It includes a type of pseudo-variable, the functions to get and set the pseudo-variable value, the parameter with name and index specifiers and the list to transformations associated for that specific instance of the pseudo-variable.
...
typedef int (*pv_getf_t) (struct sip_msg*, pv_param_t*, pv_value_t*);
typedef int (*pv_setf_t) (struct sip_msg*, pv_param_t*, int, pv_value_t*);
typedef struct _pv_spec {
pv_type_t type; /* type of PV */
pv_getf_t getf; /* get PV value function */
pv_setf_t setf; /* set PV value function */
pv_param_t pvp; /* parameter to be given to get/set functions */
void *trans; /* transformations */
} pv_spec_t, *pv_spec_p;
...
The types are defined in pvar.h and are used to detect the type of core variables. Sometime is useful to filter out pseudo-variables, for example when you want to allow only some type as parameter to a function or module, e.g., only AVPs.
Such structure resides behind each occurrence of a pseudo-variable in configuration file.
The structure that one has to fill in order to add a new pseudo-variable. There is an array of such objects in the core, in file pvar.c, and it is possible to export such structure with the module interface.
...
typedef int (*pv_parse_name_f)(pv_spec_p sp, str *in);
typedef int (*pv_parse_index_f)(pv_spec_p sp, str *in);
typedef int (*pv_init_param_f)(pv_spec_p sp, int param);
typedef struct _pv_export {
str name; /* class name of PV */
pv_type_t type; /* type of PV */
pv_getf_t getf; /* function to get the value */
pv_setf_t setf; /* function to set the value */
pv_parse_name_f parse_name; /* function to parse the inner name */
pv_parse_index_f parse_index; /* function to parse the index of PV */
pv_init_param_f init_param; /* function to init the PV spec */
int iparam; /* parameter for the init function */
} pv_export_t;
...
Practically, to add the pseudo-variable you have to give the classname and implement the functions to:
get the value of the pseudo-variable (required)
set the value of the pseudo-variable (optional)
parse the inner name (optional)
parse the index (optional)
initialize the pseudo-variable spec (optional)
The optional attributes can be left NULL. iparam is used together with function init_param.
We will show how to add a simple pseudo-variable in the core, later will show how to add a pseudo-variable with a inner name via module interface. $ru (request URI) is taken as example. This pseudo-variable is read/write, so we have to implement the get and set functions. These are in file module_k/pv/pv_core.c.
...
static int pv_get_ruri(struct sip_msg *msg, pv_param_t *param,
pv_value_t *res)
{
if(msg==NULL || res==NULL)
return -1;
if(msg->first_line.type == SIP_REPLY) /* REPLY doesn't have a ruri */
return pv_get_null(msg, param, res);
if(msg->parsed_uri_ok==0 /* R-URI not parsed*/ && parse_sip_msg_uri(msg)<0)
{
LM_ERR("failed to parse the R-URI\n");
return pv_get_null(msg, param, res);
}
if (msg->new_uri.s!=NULL)
return pv_get_strval(msg, param, res, &msg->new_uri);
return pv_get_strval(msg, param, res, &msg->first_line.u.request.uri);
}
...
int pv_set_ruri(struct sip_msg* msg, pv_param_t *param,
int op, pv_value_t *val)
{
struct action act;
struct run_act_ctx h;
char backup;
if(msg==NULL || param==NULL || val==NULL || (val->flags&PV_VAL_NULL))
{
LM_ERR("bad parameters\n");
return -1;
}
if(!(val->flags&PV_VAL_STR))
{
LM_ERR("str value required to set R-URI\n");
goto error;
}
memset(&act, 0, sizeof(act));
act.val[0].type = STRING_ST;
act.val[0].u.string = val->rs.s;
backup = val->rs.s[val->rs.len];
val->rs.s[val->rs.len] = '\0';
act.type = SET_URI_T;
init_run_actions_ctx(&h);
if (do_action(&h, &act, msg)<0)
{
LM_ERR("do action failed\n");
val->rs.s[val->rs.len] = backup;
goto error;
}
val->rs.s[val->rs.len] = backup;
return 0;
error:
return -1;
}
...
The parameters to the functions are:
msg - the SIP message currenty processed
param - the param field from PV spec structure
op - the assign operation for set function
value - pointer to a pv_value_t structure. It is out parameter for get function and in parameter for set function.
The functions return 0 in case of success and <0 in case of error.
In the get function, it checks whether there is a new request URI values and return that. If not, returns the URI from the original SIP message. It takes care that the URI is parsed, so it is valid.
In the set function, it checks to be sure that the value to assign is a string, and then calls the internal SET_URI_T action.
The last step is to add the proper entry in the pseudo-variables table (see modules_k/pv/pv.c) -- remember that this is required only for pseudo-variables included in core, not for the ones exported by modules.
...
static pv_export_t mod_pvs[] = {
...
{{"ruri", (sizeof("ruri")-1)}, /* */
PVT_RURI, pv_get_ruri, pv_set_ruri,
0, 0, 0, 0},
...
{{0,0}, 0, 0, 0, 0, 0, 0, 0}
};
...
... and do not forget to document in the Pseudo-Variable Cookbok.
The transformations are strictly related to pseudo-variables. They are properties that can be associated to instances of pseudo-variables. A transformation produces changes to the value returned by a pseudo-variable. There can be a chain of transformations assigned to same instance of a pseudo-variable.
An example of a transformation is to get a substring from the value returned by a pseudo-variable. Another one is to get the length of the values returned by a pseudo-variable.
The value of a pseudo-variable with a chain of transformations is evaluated as:
get the value of the pseudo-variable
apply the operation specified by the first transformation to the value returned by the pseudo-variable
apply the operation specified by the current transformation to the value returned by the previous transformation. Go to next transformation.
the value returned by the last transformation is returned to script or to calling C code.
Behind each transformation it is a function that does value (pv_value_t) manipulation. It has as input such a value and as output another value, stored over the input value. The transformation are implemented mainly in Kamailio modules, data structures and API are in file pvar.h. Many transformations are effectively implemented in modules_k/pv/pv_trans.{c,h}.
The transformations are given in between the pharantesis around the parenthesis of a pseudo-variable. The transformation name and parameters are enclosed in between curly brackets { }. The grammar for a transformation specifier:
...
'{' classname '.' innername ( ',' parameter )* '}'
...
The tokens are:
classname - string identifying the class of transformation. For example:
's' - string transformations
'uri' - URI transformations
'param' - parameter transformations
innername - string identifying the operation within the class of transformations
parameter - the parameter to the transformation. There can be transformation with no parameters, one or more parameters.
Example of existing transformations:
...
{s.substr,1,2} - return the string with second and the third characters (substring of length 2 from the
second character)
{uri.user} - return the user part of the SIP URI stored in the pseudo-variable on which this transformation
is applied
...
Internally, to the classname of a transformation it is associated type, an integer number, and to the innername a subtype, also an integer number. Constants and definitions are in file transformations.h
...
typedef struct _tr_param {
int type; /* type of the parameter value */
union {
int n; /* the integer value of the parameter */
str s; /* the string value of the parameter */
void *data; /* pseudo-variable spec of the parameter */
} v;
struct _tr_param *next; /* link to next parameter */
} tr_param_t, *tr_param_p;
typedef int (*tr_func_t) (struct sip_msg *, tr_param_t*, int, pv_value_t*);
typedef struct _trans {
str name; /* full name of the transformation */
int type; /* the id of the transformation class */
int subtype; /* the id of the transformation inner name */
tr_func_t trf; /* the function to be executed when applying the transformation */
tr_param_t *params; /* the parameters for this transformation */
struct _trans *next; /* link to next transformation to be applied to same pseudo-variable */
} trans_t, *trans_p;
...
The parameters of the function to be executed for a transformation:
msg - the SIP message currently processed
param - the list with the parameters of the transformation
subtype - the subtype of the transformation
value - pointer to the value (pv_value_t) to apply transformation on it and store the result
There is one function for each transformation class, the exact operation to be applied is given via subtype. The structure trans_t is what stands behind each transformation occurrence.
The transformation framework keeps for each transformation class a function to parse the innername and the parameters, plus a function to execute when the transformation need to be applied. To add new transformations, you have to implement the two functions.
Exemplifying with transformation s.len - it returns the length of the string value of a pseudo-variable. The type TR_STRING and subtype TR_S_LEN are added in file modules_k/pv/pv_trans.h - these are internal IDs used for runtime optimizations.
The function tr_parse_string() in file modules_k/pv/pv_trans.c is implementing the parser of the class s. In this function, if the inner name is len it sets the subtype accordingly.
...
if(name.len==3 && strncasecmp(name.s, "len", 3)==0)
{
t->subtype = TR_S_LEN;
return p;
}
...
The transformation parser is now extended. Next is the interpreter, the function tr_eval_str(...) - the evaluation function will be associated to string transformation by the parser function tr_parse_string().
...
switch(subtype)
{
case TR_S_LEN:
if(!(val->flags&PV_VAL_STR))
val->rs.s = int2str(val->ri, &val->rs.len);
val->flags = PV_TYPE_INT|PV_VAL_INT|PV_VAL_STR;
val->ri = val->rs.len;
val->rs.s = int2str(val->ri, &val->rs.len);
break;
...
The content of the pv_value_t variable is replaced with the length of the string representation of its initial value. An example of usage is shown next - get the length of request URI:
...
$var(x) = $(ru{s.len});
...
To make the transformations available to the core API, you have to register them. You can do it via mod_register(...) function. Note that this function is executed when the module is loaded, making possible to use the transformation in module parameters and configuration file operations. See modules_k/pv/pv.c:
...
static tr_export_t mod_trans[] = {
{ {"s", sizeof("s")-1}, /* string class */
tr_parse_string },
{ {"nameaddr", sizeof("nameaddr")-1}, /* nameaddr class */
tr_parse_nameaddr },
{ {"uri", sizeof("uri")-1}, /* uri class */
tr_parse_uri },
{ {"param", sizeof("param")-1}, /* param class */
tr_parse_paramlist },
{ {"tobody", sizeof("tobody")-1}, /* param class */
tr_parse_tobody },
{ { 0, 0 }, 0 }
};
...
int mod_register(char *path, int *dlflags, void *p1, void *p2)
{
return register_trans_mod(path, mod_trans);
}
...
These are integer numbers that collect information about Kamailio internals. They are providing real-time feedback about health and load of an Kamailio instance. In fact, they are represented by an integer variable or a function that returns an integer.
The statistics engine is implemented in the files lib/kcore/statistics..{c,h} - practically they are part of internal library kcore. If you want to extend it, you have to read and understand the code in those file. The purpose of this chapter is to teach how to add new statistic variables.
You have to include the header file lib/kcore/statistics.h and declare the statistic variable. We exemplify with the statistic stored_messages from module msilo. In the file modules/msilo/msilo.c.
... #include "../../lib/kcore/statistics.h" stat_var* ms_stored_msgs; ...
Next is to register the statistic to the engine, which can done there via register_module_stats(...) function when you have an array of new statistics.
...
stat_export_t msilo_stats[] = {
{"stored_messages" , 0, &ms_stored_msgs },
...
if (register_module_stats( exports.name, msilo_stats)!=0 ) {
LM_ERR("failed to register core statistics\n");
return -1;
}
...
Alternative is to use the function register_stat(...) defined in lib/kcore/statistics.{c,h}.
... int register_stat( char *module, char *name, stat_var **pvar, int flags); ...
The parameters are:
module - name of the module exporting the statistic
name - name of the statistic
var - where the statistic value will be stored
flags - flags describing the statistic
Updating the value of the statistic is done in function m_store(...), once a new message is stored in database.
... update_stat(ms_stored_msgs, 1); ...
There are three macros that help to deal with statistic values easily.
update_stat (stat, val) - add to the statistic value the val. val can be negative as well, resulting in substraction.
reset_stat (stat) - set the value of the statistic to 0
get_stat_val (stat) - return the value of the statistic
A topic that won't be involved very much in the development of new features, but important to understand as it is one of the most discussed issues related to Kamailio.
Many are surprised to discover that even they remove a header from the original SIP message, in the configuration file, when they test later for header existence it is still then. Why? Because the data lumps are behind the remove operations.
The modifications to the original SIP message instructed from configuration file are not applied immediately. They are actually added in a list of operations to be done. Practically, changing the content of the SIP message from the configuration file translates in creating a diff (like in diff/patch tools from Unix/Linux systems) and putting it in the list. The diffs are applied after the configuration file is executed, before sending the SIP message further to the network.
Note that in config of Kamailio 3.x, you can use msg_apply_changes() exported by textopsx module to apply immediately the changes done to the content of the SIP message.
There are two types of diff operations:
add content - this diff command is specified by the position in the original SIP message and the value to be added there. The value can be a static string, or a special marker to be interpreted later, when required information is available. For the later, it is the case of Record-Route headers where it is needed to set the IP address of the socket that is used to send the message further. That address is detected just before sending through the socket.
remove content - this diff command is specified by the position in the original SIP message and the length to be deleted.
There are two classes of data lumps:
message lumps - these lumps are associated to the SIP message currently processed. The changes incurred by these lumps are visible when the SIP message is forwarded.
reply lumps - these lumps can be used when the processed SIP message is a request and you want to add content to the reply to be sent for that request. Here cannot be lumps that delete content as the SIP reply is to be constructed from the SIP request.
Maybe future releases will touch deeper this subject, depending on the interest. If you want to investigate by yourself, start with files data_lump.{c,h} and data_lump_rpl.{c,h}.
Kamailio provides internal timers with millisecond precision. It offers developer API to:
register functions to be run every 1 second or interval of multiple seconds
register functions to run every millisecond or interval of multiple milliseconds
start a new timer process
The timer API is implemented in the files timer.{c,h}. If you want to extend the timer API you have to start with those files. We focus on how to add new functions to be run by timer. The timer is available after shared memory initialization.
The functions that can be given as callbacks for timer have the following prototypes:
... typedef unsigned long long utime_t; typedef void (timer_function)(unsigned int ticks, void* param); ...
Parameters are:
ticks - number of second ticks elapsed at the moment of running the function
param - parameter given when registering the callback function
Register a function to be executed by second-based timer:
... int register_timer(timer_function f, void* param, unsigned int interval); ...
Parameters:
f - callback function
param - parameter to callback function
interval - interval to execute the callback function
Register a function to start a new timer process:
... int register_timer_process(timer_function f, void* param, unsigned int interval); ...
Parameters:
f - callback function
param - parameter to callback function
interval - interval to execute the callback function
There are two functions that return the number of ticks elapsed since Kamailio started, one returning time in seconds and the other one returning the number of internal ticks.
... unsigned int get_ticks(void); utime_t get_ticks_raw(void); ...
Next we will show how the module msilo register a timer function to clean the stored messages. See modules/msilo/msilo.c.
... #include "../../timer.h" ... void m_clean_silo(unsigned int ticks, void *); ...
Registration to the second-based timer is done in function mod_init().
... register_timer(m_clean_silo, 0, ms_check_time); ...
Function implementation is:
...
/**
* - cleaning up the messages that got reply
* - delete expired messages from database
*/
void m_clean_silo(unsigned int ticks, void *param)
{
msg_list_el mle = NULL, p;
db_key_t db_keys[MAX_DEL_KEYS];
db_val_t db_vals[MAX_DEL_KEYS];
db_op_t db_ops[1] = { OP_LEQ };
int n;
LM_DBG("cleaning stored messages - %d\n", ticks);
msg_list_check(ml);
mle = p = msg_list_reset(ml);
n = 0;
while(p)
{
if(p->flag & MS_MSG_DONE)
{
#ifdef STATISTICS
if(p->flag & MS_MSG_TSND)
update_stat(ms_dumped_msgs, 1);
else
update_stat(ms_dumped_rmds, 1);
#endif
db_keys[n] = &sc_mid;
db_vals[n].type = DB1_INT;
db_vals[n].nul = 0;
db_vals[n].val.int_val = p->msgid;
LM_DBG("cleaning sent message [%d]\n", p->msgid);
n++;
if(n==MAX_DEL_KEYS)
{
if (msilo_dbf.delete(db_con, db_keys, NULL, db_vals, n) < 0)
LM_ERR("failed to clean %d messages.\n",n);
n = 0;
}
}
if((p->flag & MS_MSG_ERRO) && (p->flag & MS_MSG_TSND))
{ /* set snd time to 0 */
ms_reset_stime(p->msgid);
#ifdef STATISTICS
update_stat(ms_failed_rmds, 1);
#endif
}
#ifdef STATISTICS
if((p->flag & MS_MSG_ERRO) && !(p->flag & MS_MSG_TSND))
update_stat(ms_failed_msgs, 1);
#endif
p = p->next;
}
if(n>0)
{
if (msilo_dbf.delete(db_con, db_keys, NULL, db_vals, n) < 0)
LM_ERR("failed to clean %d messages\n", n);
n = 0;
}
msg_list_el_free_all(mle);
/* cleaning expired messages */
if(ticks%(ms_check_time*ms_clean_period)<ms_check_time)
{
LM_DBG("cleaning expired messages\n");
db_keys[0] = &sc_exp_time;
db_vals[0].type = DB1_INT;
db_vals[0].nul = 0;
db_vals[0].val.int_val = (int)time(NULL);
if (msilo_dbf.delete(db_con, db_keys, db_ops, db_vals, 1) < 0)
LM_DBG("ERROR cleaning expired messages\n");
}
}
...
The function deletes from database the messages that were succesfully delivered and the messages that were stored for too long time in database and the recipient was not online or not able to receive them.
Sometime might be better to have your own timer process, not to disturb the operations done by other timer function - recommended when you are doing operation that may take a while on timer basis.
You can create as many timer processes as you need - it takes two steps:
in mod_init() tell to timer API how many processes you want to create
in child_init() for MAIN child, fork the timer processes with the callback function
...
/**
* init module function
*/
static int mod_init(void)
{
...
register_dummy_timers(1);
...
}
...
/**
* init module children
*/
static int child_init(int rank)
{
...
if (rank==PROC_MAIN)
{
if(fork_dummy_timer(PROC_TIMER, "MY MOD TIMER", 1 /*socks flag*/,
my_timer_callback, my_timer_param, 1 /*sec*/) < 0) {
LM_ERR("failed to register timer routine as process\n");
return -1; /* error */
}
}
...
}
...
The easiest way to write extensions for Kamailio is to extend existing modules or create new ones. Most of the features available in the configuration file are exported via module functions.
Kamailio modules in a pretty simple concept, are objects that export a set of parameters to control the internals and a set of functions that can be used in the configuration file. In fact, they are shared library files.
There are no modules to be automatically loaded, the configuration file must explicitly include the directive to load a module.
... loadmodule "/path/to/module.so" ...
Each module has to export a structure struct module_exports with the name exports.
The main structure that has to be exported by a module. It is defined in file sr_module.h.
Example 16.1. module_exports definition
...
struct module_exports{
char* name; /* null terminated module name */
unsigned int dlflags; /* flags for dlopen */
cmd_export_t* cmds; /* null terminated array of the exported
commands */
param_export_t* params; /* null terminated array of the exported
module parameters */
stat_export_t* stats; /* null terminated array of the exported
module statistics */
mi_export_t* mi_cmds; /* null terminated array of the exported
MI functions */
pv_export_t* items; /* null terminated array of the exported
module items (pseudo-variables) */
proc_export_t* procs; /* null terminated array of the additional
processes reqired by the module */
init_function init_f; /* Initialization function */
response_function response_f; /* function used for responses,
returns yes or no; can be null */
destroy_function destroy_f; /* function called when the module should
be "destroyed", e.g: on kamailio exit */
child_init_function init_child_f;/* function called by all processes
after the fork */
};
...
The comments in the definition are explanatory, each internal structure and data type is detailed in the next sections.
Starting with version 3.0, there are two module interfaces: one specific to Kamailio flavour and the other one specific for SER flavour. A third one will merge the two in the near future. At this moment, each module has to specify in the Makefile what kind of interface implements. In this chapter, the focus is on writing modules implementing Kamailio specific module interface.
The structure corresponds to a function exported by modules
...
struct cmd_export_ {
char* name; /* null terminated command name */
cmd_function function; /* pointer to the corresponding function */
int param_no; /* number of parameters used by the function */
fixup_function fixup; /* pointer to the function called to "fix" the
parameters */
free_fixup_function
free_fixup; /* pointer to the function called to free the
"fixed" parameters */
int flags; /* Function flags */
};
typedef struct cmd_export_ cmd_export_t;
...
Flags can be a bit mask of:
REQUEST_ROUTE - the function can be used in request route blocks
FAILURE_ROUTE - the function can be used in failure_route blocks
ONREPLY_ROUTE - the function can be used in onreply_route blocks
BRANCH_ROUTE - the function can be used in branch_route blocks
ONSEND_ROUTE - the function can be used in onsend_route block
ANY_ROUTE - the function can be used in any route block
The structure specifies a parameter exported by a module.
...
struct param_export_ {
char* name; /* null terminated param. name */
modparam_t type; /* param. type */
void* param_pointer; /* pointer to the param. memory location or to function to set the parameter */
};
typedef struct param_export_ param_export_t;
...
The type can be:
STR_PARAM - parameter takes a string value
INT_PARAM - parameter takes an integer value
USE_FUNC_PARAM - this must be used in combination with one from the above. Means that internally there is a function called every time the parameter is set, instead of setting the value to a variable.
When using USE_FUNC_PARAM flag, the param_pointer must be set to a function with the following type:
... typedef int (*param_func_t)( modparam_t type, void* val); ...
Parameters are:
type - the type of value set to the parameter in the config file
val - pointer to the value set in the configuration file
The function has to return 0 in case of success.
This field is no longer active, it is kept for no-error at compilation time during a transition period and will be removed in the future. To create new application processes, you have to use a two steps mechanism that ensures inheriting proper TCP/TLS handling.
First you have to declare in mod_init() how many processes you want to start, the fork new processes in init_child() for RANK_PROC_MAIN:
...
static int mod_init(void)
{
...
/* add space for one extra process */
register_procs(1);
...
}
...
static int child_init(int rank)
{
int pid;
...
if (rank==PROC_MAIN) {
pid=fork_process(PROC_NOCHLDINIT, "MY PROC DESCRIPTION", 1);
if (pid<0)
return -1; /* error */
if(pid==0){
/* child */
/* initialize the config framework */
if (cfg_child_init())
return -1;
my_process_main_function(...);
}
}
...
return 0;
}
...
register_procs(no) takes as parameter the number of processes to be created. fork_process(...) takes as parameters: flag specifying wheter to execute child_init() functions for the new process; string with description of the process; flag specifying whether to create internal unix sockets or not for the new process (needed for TCP/TLS communication, use 1 to be safe always).
Typical module implementations for such functionality are the MI transports module. They require a special process to listen to the MI transport layer.
The structure allow to export statistics variables from your module.
...
typedef struct stat_export_ {
char* name; /* null terminated statistic name */
int flags; /* flags */
stat_var** stat_pointer; /* pointer to the variable's mem location *
* NOTE - it's in shm mem */
} stat_export_t;
...
This field is currently in passive mode inside module_exports structure. You have to explicitely register the statistics inside mod_init() via register_module_stats(). For example in modules_k/msilo:
...
stat_export_t msilo_stats[] = {
{"stored_messages" , 0, &ms_stored_msgs },
{"dumped_messages" , 0, &ms_dumped_msgs },
{"failed_messages" , 0, &ms_failed_msgs },
{"dumped_reminders" , 0, &ms_dumped_rmds },
{"failed_reminders" , 0, &ms_failed_rmds },
{0,0,0}
};
...
static int mod_init(void)
{
...
/* register statistics */
if (register_module_stats( exports.name, msilo_stats)!=0 ) {
LM_ERR("failed to register core statistics\n");
return -1;
}
...
}
...
</programlisting>
<para>
For more see the chapter <emphasis role="strong">Statistics</emphasis>.
</para>
</section>
<section id="c16t_mi_export_t">
<title>mi_export_t type</title>
<para>
The structure to export MI commands. For more see the chapter <emphasis role="strong">Management Interface</emphasis>.
</para>
<programlisting format="linespecific">
...
typedef struct mi_export_ {
char *name; /* name of MI command */
mi_cmd_f *cmd; /* function to be executed for the MI command */
unsigned int flags; /* flags associated to the MI command */
void *param; /* parameter to be given to the MI command */
mi_child_init_f *init_f; /* function to be executed at MI process initialization in order to
* have function 'cmd' working properly */
}mi_export_t;
...
The structure to export pseudo-variables from module. See the chapter Pseudo Variables for detailed description.
...
typedef struct _pv_export {
str name; /* class name of PV */
pv_type_t type; /* type of PV */
pv_getf_t getf; /* function to get the value */
pv_setf_t setf; /* function to set the value */
pv_parse_name_f parse_name; /* function to parse the inner name */
pv_parse_index_f parse_index; /* function to parse the index of PV */
pv_init_param_f init_param; /* function to init the PV spec */
int iparam; /* parameter for the init function */
} pv_export_t;
...
An example of module that exports pseudo-variables is modules/mqueue:
...
static pv_export_t mod_pvs[] = {
{ {"mqk", sizeof("mqk")-1}, PVT_OTHER, pv_get_mqk, 0,
pv_parse_mqk_name, 0, 0, 0 },
{ {"mqv", sizeof("mqv")-1}, PVT_OTHER, pv_get_mqv, 0,
pv_parse_mqv_name, 0, 0, 0 },
{ {0, 0}, 0, 0, 0, 0, 0, 0, 0 }
};
...
truct module_exports exports = {
"mqueue",
DEFAULT_DLFLAGS, /* dlopen flags */
cmds,
params,
0,
0, /* exported MI functions */
mod_pvs, /* exported pseudo-variables */
0, /* extra processes */
mod_init, /* module initialization function */
0, /* response function */
mod_destroy, /* destroy function */
0 /* per child init function */
};
...
These are the types of functions used in the structure module_exports.
... typedef int (*cmd_function)(struct sip_msg*, char*, char*, char*, char*, char*, char*); typedef int (*fixup_function)(void** param, int param_no); typedef int (*free_fixup_function)(void** param, int param_no); typedef int (*response_function)(struct sip_msg*); typedef void (*destroy_function)(); typedef int (*init_function)(void); typedef int (*child_init_function)(int rank); ...
Description:
cmd_function - is the type for functions implementing the commands exported to configuration file
fixup_function - is the type for function to be used to pre-compile the parameters at startup
free_fixup_function - is the type for function to be used to free the structure resulted after pre-compile processing
response_function - is the type for the functions to be register to automatically be called when a SIP reply is received by Kamailio
destroy_function - is the type for the function to be executed at shut down time, to clean up the resources used during run time (e.g., shared memory, locks, connections to database)
init_function - is the type for the function to be executed at start up, before forking children processes
child_init_function - is the type for the function to be executed for each children process, immediately after forking
These are the functions implemented by the module that can be invoked from the configuration file. It has a strict prototype. First parameter is the pointer to structure with the current processed SIP message. Next are char*. Most existing command functions have up to two char* parameters, recent extensions allow up to six such parameters.
It means that in the configuration file you can give only char* values as parameter. Kamailio provides the mechanisms to convert the values to something more meaningful for the module, during Kamailio start up, via fixup functions.
When calling from the configuration file, the structure sip_msg is not given as parameter, it is added by the config interpreter when calling the C function. The name of the function available in the configuration file may be different that the name of the C function. There can be different C functions behind the same config file function, when the number of the parameters is different.
Returning values from the command functions have a special meaning in the configuration file. The command functions return an integer value, and the config file interpreter use it as follows:
if <0 - evaluation of the return code is FALSE
if 0 - the interpreter stop executing the configuration file
if >0 - evaluation of the return code is TRUE
As the parameters of the functions exported by modules to configuration file are strings, converting the parameters to internal structures every time a module function is executed is not optimal. Most of the functions do not need the parameters as a string, but as integer, pseudo-variable names or pseudo-variables values, or even more complex structures.
Here are the fixup functions. These functions convert from plain null-terminated strings to what the developer needs. Such a function gets a pointer to the initial value and the index of the parameter for that function. Inside it the value can processed and replaced with a new structure.
Next is a fixup function that converts the string value given in configuration file to an unsigned integer.
...
int fixup_uint(void** param)
{
unsigned int ui;
str s;
s.s = (char*)*param;
s.len = strlen(s.s);
if(str2int(&s, &ui)==0)
{
pkg_free(*param);
*param=(void *)(unsigned long)ui;
return 0;
}
LM_ERR("bad number <%s>\n", (char *)(*param));
return E_CFG;
}
/**
* fixup for functions that get one parameter
* - first parameter is converted to unsigned int
*/
int fixup_uint_null(void** param, int param_no)
{
if(param_no != 1)
{
LM_ERR("invalid parameter number %d\n", param_no);
return E_UNSPEC;
}
return fixup_uint(param);
}
...
fixup_uint(...) is a helper function, fixup_uint_null(...) is a fixup function that can be used for config function that get one char* parameter that need to be interpreted as unsigned integer.
The files mod_fix.{c,h} implement a set of common fixup functions you can. Check that files before implementing a new fixup function.
Recent work is focusing to add free fixup functions, that will help to clean up properly at shut down and use exported functions dynamically at run time from linked applications.
Here we show the steps to develop new modules, exemplifying with code from different modules.
Prior starting writing code, check with developers whether that functionality is already implemented. Also try to identify whether the extension fits better in an existing module or needs to be created a new one.
The first decision to be taken. It must be suggestive for the functionality. There are some rules to be followed when implementing certain modules.
when writing a DB driver module, the module name should start with db_.
when writing a MI transport, the module name should start with mi_
when writing a Presence Server extension, the name should start with presence_
when writing a PUA extension, the name should start with pua_
The rules are enforced for coherence in grouping related functionalities.
Create the directory for your new module.
... mkdir modules/my_new_module ...
Source code for a module has to be placed in a directory inside subfolders: modules, modules_k or modules_s. In each module directory you have to create a Makefile that specify the dependencies of the module (e.g., compile flags and internal/external linking libraries) as well as module interface type.
For example, modules_k/regex implements Kamailio module interface and depends on external libpcre library and internal kmi library. Its Makefile looks like:
... include ../../Makefile.defs auto_gen= NAME=regex.so BUILDER = $(shell which pcre-config) ifeq ($(BUILDER),) PCREDEFS=-I$(LOCALBASE)/include -I/usr/local/include -I/opt/include \ -I/usr/sfw/include PCRELIBS=-L$(LOCALBASE)/lib -L/usr/local/lib -L/usr/sfw/lib \ -L/opt/lib -lpcre else PCREDEFS = $(shell pcre-config --cflags) PCRELIBS = $(shell pcre-config --libs) endif DEFS+=$(PCREDEFS) LIBS=$(PCRELIBS) DEFS+=-DOPENSER_MOD_INTERFACE SERLIBPATH=../../lib SER_LIBS+=$(SERLIBPATH)/kmi/kmi include ../../Makefile.modules ...
The NAME is specifying the name of shared object file for module. Follows a section where it tries to discover the location of external shared library libpcre and its compile time flags. These are added to Makefile variables DEFS and LIBS. To the DEFS variable has to be added also the type of interface - for Kamailio this is -DOPENSER_MOD_INTERFACE. For SER module interface it is -DSER_MOD_INTERFACE.
The internal library dependencies are provided via SER_LIBS variable, as a space separated list of the paths to libraries. In this case it is a dependency on library kmi, located at ../../lib/kmi/.
First and last lines include common Makefiles needed to build the core and modules - they have to be preserved as they are in this example.
A very simple and pretty standard template to start building you module Makefile:
... include ../../Makefile.defs auto_gen= NAME=my_new_module.so LIBS= DEFS+=-DOPENSER_MOD_INTERFACE include ../../Makefile.modules ...
The main file of the modules is where you place the structure module_exports. The common naming formats are:
my_new_module.c
my_new_module_mod.c
In this file you must include the macro MODULE_VERSION to allow Kamailio to detect whether core and the module are same version and compiled with same flags. You just simply add next line after all header files includes.
... MODULE_VERSION ...
In the configuration file, can be set integer or string values for a module parameter. The type is specified in the param_export_t structure.
We exemplify the parameters exported by the modules modules_k/cfgutils and modules_k/pv - showing one integer parameter, one string parameter and another string parameter that is set via a function.
For the parameters stored directly in a variable, you have to declare C variables of type int or char*.
...
static int initial = 10;
static char* hash_file = NULL;
static param_export_t params[]={
...
{"initial_probability", INT_PARAM, &initial},
{"hash_file", STR_PARAM, &hash_file },
...
{"shvset", STR_PARAM|USE_FUNC_PARAM, (void*)param_set_shvar },
...
{0,0,0}
};
...
In the config, one can set many times the value for a parameter. In case of parameters stored in a variable, the last one is taken. For those that use a function, it is up to the implementation what to do with each value. Actually here is the real benefit of using a function.
The param_set_shvar(...) function sets the initial value for a shared config file variable $shv(name). The function is implemented in the file modules_k/pv/pv_shv.c. Check the readme of the module to see the format of the parameter value - it includes the name of the shared variable as well as the value. So the function parses the value given from the configuration file, splits in name and value and store in a local structure.
...
int param_set_xvar( modparam_t type, void* val, int mode)
{
str s;
char *p;
int_str isv;
int flags;
int ival;
script_var_t *pkv;
sh_var_t *shv;
if(!shm_initialized()!=0)
{
LM_ERR("shm not initialized - cannot set value for PVs\n");
goto error;
}
s.s = (char*)val;
if(s.s == NULL || s.s[0] == '\0')
goto error;
p = s.s;
while(*p && *p!='=') p++;
if(*p!='=')
goto error;
s.len = p - s.s;
if(s.len == 0)
goto error;
p++;
flags = 0;
if(*p!='s' && *p!='S' && *p!='i' && *p!='I')
goto error;
if(*p=='s' || *p=='S')
flags = VAR_VAL_STR;
p++;
if(*p!=':')
goto error;
p++;
isv.s.s = p;
isv.s.len = strlen(p);
if(flags != VAR_VAL_STR) {
if(str2sint(&isv.s, &ival)<0)
goto error;
isv.n = ival;
}
if(mode==0) {
pkv = add_var(&s);
if(pkv==NULL)
goto error;
if(set_var_value(pkv, &isv, flags)==NULL)
goto error;
} else {
shv = add_shvar(&s);
if(shv==NULL)
goto error;
if(set_shvar_value(shv, &isv, flags)==NULL)
goto error;
}
return 0;
error:
LM_ERR("unable to set shv parame [%s]\n", s.s);
return -1;
}
int param_set_shvar( modparam_t type, void* val)
{
return param_set_xvar(type, val, 1);
}
...
So, actually, setting the parameter setshv for module pv produces a set of operations behind.
...
modparam("pv", "shvset", "debug=i:1")
...
By setting the parameter as above results in a variable $shv(debug) initialized to 1.
The function is executed after setting the module parameters, config file is parsed completely, shared memory and locking system are initialized.
The main purpose of this function is to check the sanity of the module parameter, load data from storage systems, initialize the structured to be used at runtime. Here is the example from modules_k/cfgutils module:
...
static int mod_init(void)
{
if(register_mi_mod(exports.name, mi_cmds)!=0)
{
LM_ERR("failed to register MI commands\n");
return -1;
}
if (!hash_file) {
LM_INFO("no hash_file given, disable hash functionality\n");
} else {
if (MD5File(config_hash, hash_file) != 0) {
LM_ERR("could not hash the config file");
return -1;
}
LM_DBG("config file hash is %.*s", MD5_LEN, config_hash);
}
if (initial_prob > 100) {
LM_ERR("invalid probability <%d>\n", initial_prob);
return -1;
}
LM_DBG("initial probability %d percent\n", initial_prob);
probability=(int *) shm_malloc(sizeof(int));
if (!probability) {
LM_ERR("no shmem available\n");
return -1;
}
*probability = initial_prob;
gflags=(unsigned int *) shm_malloc(sizeof(unsigned int));
if (!gflags) {
LM_ERR(" no shmem available\n");
return -1;
}
*gflags=initial_gflags;
if(_cfg_lock_size>0 && _cfg_lock_size<=10)
{
_cfg_lock_size = 1<<_cfg_lock_size;
_cfg_lock_set = lock_set_alloc(_cfg_lock_size);
if(_cfg_lock_set==NULL || lock_set_init(_cfg_lock_set)==NULL)
{
LM_ERR("cannot initiate lock set\n");
return -1;
}
}
return 0;
}
...
First in the function is registering MI commands and then is the handling of the config hashing. If the appropriate parameter is not set, it is initialized to the config file used by Kamailio. Then is computed the hash value that will be used for comparison, later at runtime. Next is checking the probability parameter and create the variable in share memory to store it. At the end it initializes the variables for global flags and lock sets.
The module init function must return 0 in case of success.
This is the function called just after Kamailio forks its worker processes. If Kamailio is set in non-fork module, the function is called for the main process after calling the module init function.
In this function must be added the operations that has to be taken for each worker or special processes only once during the runtime, at the start up time. Example of such operations are to open the connection to database, set the intial values for local variables per process.
The function gets as parameter the rank of the child process. The rank is a positive number if it is a worker process and negative for special processes like timer processes or TCP attendant. The defines with these special ranks are in file sr_module.h.
As an example, we show the child_init function of the module speeddial. The operations there are for opening the connection to database.
...
static int child_init(int rank)
{
if (rank==PROC_INIT || rank==PROC_MAIN || rank==PROC_TCP_MAIN)
return 0; /* do nothing for the main process */
db_handle = db_funcs.init(&db_url);
if (!db_handle)
{
LM_ERR("failed to connect database\n");
return -1;
}
return 0;
}
...
The child init function must return 0 in case of success.
It is the function to be called when Kamailio is stopped. The main purpose is to clean up the resources created and used at initialization and/or runtime. For the module cfgutils means to free the variable allocated in shared memory for keeping the probability and destroying the global flags and lock sets.
...
static void mod_destroy(void)
{
if (probability)
shm_free(probability);
if (gflags)
shm_free(gflags);
if(_cfg_lock_set!=NULL)
{
lock_set_destroy(_cfg_lock_set);
lock_set_dealloc(_cfg_lock_set);
}
}
...
The module cfgutils exports a functions stop and wait for a period of time the execution of the configuration file. It is an interface the the standard C function sleep(...). Takes as parameter the number of the seconds to wait.
As the parameter is given as string, but it is actually an integer value, a fixup function is used. It is in the list of the fixup functions exported by mod_fix.h. The fixup function fixup_uint_null(...) is shown few sections above.
...
static cmd_export_t cmds[]={
...
{"sleep", (cmd_function)m_sleep, 1, fixup_uint_null, 0,
ANY_ROUTE},
...
{0, 0, 0, 0, 0, 0}
};
...
static int m_sleep(struct sip_msg *msg, char *time, char *str2)
{
LM_DBG("sleep %lu seconds\n", (unsigned long)time);
sleep((unsigned int)(unsigned long)time);
return 1;
}
...
In the C function, as shown in the above example, the fitst parameter is cased to integer, because the fixup function replaced the original string value with the integer representation.
This function return all the time 1 (TRUE in the configuration file). The function in C (m_sleep(...)) has a different name than the one that can be used in the Kamailio configuration file (sleep(...)). Next shows how this function can be called in the configuration file to introduce a pause of 3 seconds.
...
sleep("3");
...
The chapter dedicated to Pseudo Variables presents the structure pv_export_t. When a module exports pseudo-variables, a null terminated array of pv_export_t is included in the structure module_exports.
The module pv exports most of the pseudo-variables. We will exemplify with $time(name), showing how a class of pseudo-variables can have inner name. For that it exports the name parsing function pv_parse_time_name(...).
The name can be:
sec - to return number of seconds
min - to return number of minutes
hour - to return the hour
mday - to return the day of month
mon - to return the month
year - to return the year
wday - to return the day of week
yday - to return the day of year
isdst - return daylight saving mode
To increase the execution speed and not compare strings all the time, the name is kept internally as integer. At runtime, depending on the value, the appropriate attribute is returned.
...
static pv_export_t mod_items[] = {
...
{ {"time", (sizeof("time")-1)}, 1002, pv_get_time,
0, pv_parse_time_name, 0, 0, 0},
...
{ {0, 0}, 0, 0, 0, 0, 0, 0, 0 }
};
...
int pv_parse_time_name(pv_spec_p sp, str *in)
{
if(sp==NULL || in==NULL || in->len<=0)
return -1;
switch(in->len)
{
case 3:
if(strncmp(in->s, "sec", 3)==0)
sp->pvp.pvn.u.isname.name.n = 0;
else if(strncmp(in->s, "min", 3)==0)
sp->pvp.pvn.u.isname.name.n = 1;
else if(strncmp(in->s, "mon", 3)==0)
sp->pvp.pvn.u.isname.name.n = 4;
else goto error;
break;
case 4:
if(strncmp(in->s, "hour", 4)==0)
sp->pvp.pvn.u.isname.name.n = 2;
else if(strncmp(in->s, "mday", 4)==0)
sp->pvp.pvn.u.isname.name.n = 3;
else if(strncmp(in->s, "year", 4)==0)
sp->pvp.pvn.u.isname.name.n = 5;
else if(strncmp(in->s, "wday", 4)==0)
sp->pvp.pvn.u.isname.name.n = 6;
else if(strncmp(in->s, "yday", 4)==0)
sp->pvp.pvn.u.isname.name.n = 7;
else goto error;
break;
case 5:
if(strncmp(in->s, "isdst", 5)==0)
sp->pvp.pvn.u.isname.name.n = 8;
else goto error;
break;
default:
goto error;
}
sp->pvp.pvn.type = PV_NAME_INTSTR;
sp->pvp.pvn.u.isname.type = 0;
return 0;
error:
LM_ERR("unknown PV time name %.*s\n", in->len, in->s);
return -1;
}
...
static struct tm _cfgutils_ts;
static unsigned int _cfgutils_msg_id = 0;
int pv_get_time(struct sip_msg *msg, pv_param_t *param,
pv_value_t *res)
{
time_t t;
if(msg==NULL || param==NULL)
return -1;
if(_cfgutils_msg_id != msg->id)
{
pv_update_time(msg, &t);
_cfgutils_msg_id = msg->id;
if(localtime_r(&t, &_cfgutils_ts) == NULL)
{
LM_ERR("unable to break time to attributes\n");
return -1;
}
}
switch(param->pvn.u.isname.name.n)
{
case 1:
return pv_get_uintval(msg, param, res, (unsigned int)_cfgutils_ts.tm_min);
case 2:
return pv_get_uintval(msg, param, res, (unsigned int)_cfgutils_ts.tm_hour);
case 3:
return pv_get_uintval(msg, param, res, (unsigned int)_cfgutils_ts.tm_mday);
case 4:
return pv_get_uintval(msg, param, res,
(unsigned int)(_cfgutils_ts.tm_mon+1));
case 5:
return pv_get_uintval(msg, param, res,
(unsigned int)(_cfgutils_ts.tm_year+1900));
case 6:
return pv_get_uintval(msg, param, res,
(unsigned int)(_cfgutils_ts.tm_wday+1));
case 7:
return pv_get_uintval(msg, param, res,
(unsigned int)(_cfgutils_ts.tm_yday+1));
case 8:
return pv_get_sintval(msg, param, res, _cfgutils_ts.tm_isdst);
default:
return pv_get_uintval(msg, param, res, (unsigned int)_cfgutils_ts.tm_sec);
}
}
...
Functions in pseudo-variable API return 0 in case of success and <0 in case of error.
MI commands exported by a module are in a null-terminated array of structures mi_export_t, include in module_exports.
One of the MI commands exported by module pv is the shv_set. It can be used to set the value of a shared variable via MI. The command takes three parameters: name of the shared variable, the type of the value and the value. The C wrapper of the command is the function mi_shvar_set(...).
...
static mi_export_t mi_cmds[] = {
...
{ "shv_set" , mi_shvar_set, 0, 0, 0 },
...
{ 0, 0, 0, 0, 0}
};
struct mi_root* mi_shvar_set(struct mi_root* cmd_tree, void* param)
{
str sp;
str name;
int ival;
int_str isv;
int flags;
struct mi_node* node;
sh_var_t *shv = NULL;
node = cmd_tree->node.kids;
if(node == NULL)
return init_mi_tree( 400, MI_SSTR(MI_MISSING_PARM_S));
name = node->value;
if(name.len<=0 || name.s==NULL)
{
LM_ERR("bad shv name\n");
return init_mi_tree( 500, MI_SSTR("bad shv name"));
}
shv = get_shvar_by_name(&name);
if(shv==NULL)
return init_mi_tree(404, MI_SSTR("Not found"));
node = node->next;
if(node == NULL)
return init_mi_tree(400, MI_SSTR(MI_MISSING_PARM_S));
sp = node->value;
if(sp.s == NULL)
return init_mi_tree(500, MI_SSTR("type not found"));
flags = 0;
if(sp.s[0]=='s' || sp.s[0]=='S')
flags = VAR_VAL_STR;
node= node->next;
if(node == NULL)
return init_mi_tree(400, MI_SSTR(MI_MISSING_PARM_S));
sp = node->value;
if(sp.s == NULL)
{
return init_mi_tree(500, MI_SSTR("value not found"));
}
if(flags == 0)
{
if(str2sint(&sp, &ival))
{
LM_ERR("bad integer value\n");
return init_mi_tree( 500, MI_SSTR("bad integer value"));
}
isv.n = ival;
} else {
isv.s = sp;
}
lock_shvar(shv);
if(set_shvar_value(shv, &isv, flags)==NULL)
{
unlock_shvar(shv);
LM_ERR("cannot set shv value\n");
return init_mi_tree( 500, MI_SSTR("cannot set shv value"));
}
unlock_shvar(shv);
LM_DBG("$shv(%.*s) updated\n", name.len, name.s);
return init_mi_tree( 200, MI_OK_S, MI_OK_LEN);
}
...
The command returns the code 200 in case of success.
It happens to need worker processed that do a different job than handling the SIP traffic. It is the case for the MI transport modules or the xmpp gateway. These processes listen on an input stream different than the SIP ports.
The next example is from module xmpp. The function will start the process that is listening on a pipe for messages coming from SIP side and create connections to the XMPP servers. Based on configuration option, the module will act as a XMPP component or server. Remember that you have to declare how many new processes you want to start in mod_init() and use fork_process() in child_init() to effectively start the new processes.
...
static proc_export_t procs[] = {
{"XMPP receiver", 0, 0, xmpp_process, 1 },
{0,0,0,0,0}
};
...
static void xmpp_process(int rank)
{
/* if this blasted server had a decent I/O loop, we'd
* just add our socket to it and connect().
*/
close(pipe_fds[1]);
LM_DBG("started child connection process\n");
if (!strcmp(backend, "component"))
xmpp_component_child_process(pipe_fds[0]);
else if (!strcmp(backend, "server"))
xmpp_server_child_process(pipe_fds[0]);
}
...
/**
* initialize module
*/
static int mod_init(void) {
...
/* add space for one extra process */
register_procs(1);
...
}
...
/**
* initialize child processes
*/
static int child_init(int rank)
{
int pid;
if (rank==PROC_MAIN) {
pid=fork_process(PROC_NOCHLDINIT, "XMPP Manager", 1);
if (pid<0)
return -1; /* error */
if(pid==0){
/* child */
/* initialize the config framework */
if (cfg_child_init())
return -1;
xmpp_process(1);
}
}
return 0;
}
...
The function gets as parameter the rank of the process.
The structure module_exports of the module cfgutils includes some of the structures detailed in the examples seen in the previous sections.
...
struct module_exports exports = {
"cfgutils",
DEFAULT_DLFLAGS, /* dlopen flags */
cmds, /* exported functions */
params, /* exported parameters */
0, /* exported statistics */
mi_cmds, /* exported MI functions */
mod_items, /* exported pseudo-variables */
0, /* extra processes */
mod_init, /* module initialization function */
0, /* response function*/
mod_destroy, /* destroy function */
0 /* per-child init function */
};
...
Between version 1.5 and 3.0, there were major refactorings inside the code, as part Kamailio and SER source code integration, several of them affecting the existing modules. If you had some internally developed modules, in this chapter you can find the hints that should make the upgrade easier.
Three changes affected the old Kamailio modules:
support for many module interfaces - each module write can choose what module interface to implement and export
support for internal libraries - code that usually resided in the core, but was not for general purpose, just shared by several modules, can be now part of an internal library
several fields in module exports became passive - this is a result of moving some code in internal libraries, thus they are not handled by the core anymore
Since you developed the module for Kamailio v1.x, it is clear you have implemented the Kamailio-specific module interface. What you need to do: edit module Makefile and add -DOPENSER_MOD_INTERFACE to DEFS variable:
... DEFS+=-DOPENSER_MOD_INTERFACE ...
Some examples of code that was during the past in core and now is part of internal libraries:
Database API
MI API
Statistics API
Helper functions for SIP message parsing
To get your module compiling, you have to update the paths to include directives. Internal libraries are located in directories inside lib/. For example, what was in v1.x as:
... #include "../../db/db.h" ...
is in v3.x:
... #include "../../lib/srdb1/db.h" ...
You may need also to update the names of data structures and types, or API functions.
In the Makefile, you have to list the interal library dependencies. For example, a module that connects to database and exports MI commands has in Makefile:
... SERLIBPATH=../../lib SER_LIBS+=$(SERLIBPATH)/srdb1/srdb1 SER_LIBS+=$(SERLIBPATH)/srdb1/kmi SER_LIBS+=$(SERLIBPATH)/kcore/kcore ...
Internal kcore library collects code from old v1.x that didn't meet the requirements of the new architecture for the core v3.x. It also includes the code for statistics API - it most of the cases, you may need to link old Kamailio modules to it.
Regarding the passive fields in the module exports, practically they are:
MI commands
Extra processes
Statistics
To get them registered to the core framework, you have to use now dedicated functions in mod_init() and child_init(). See the specific chapters in this guide that approach these topics for real examples of how to do it for each one.
Starting with v3.0, Kamailio has support for internal libraries. They are collection of C functions to be used by many modules, but not having a general purpose for SIP server in order to be included in core.
An internal library is automatically loaded at runtime if there is a module in config file that requires code from it
Among benefits of internal libraries:
core is smaller - more suitable for embedded devices, as well as it is more stable
overall footprint is smaller - duplicated code in several modules can be collected in an internal library
development flexibility - code offering same functionality by a different implementation can co-exist, allowing to switch and test which one is better, without adding/removing code from code or modules
The library has to be added as a sub-directory of lib/ folder. For example the trie library is located in lib/trie/.
When adding a new internal library, simply create a folder for it and place the Makefile, source code and header files inside it.
The Makefile for internal library specify name, version and external dependencies for it.
... include ../../Makefile.defs auto_gen= NAME:=trie MAJOR_VER=1 MINOR_VER=0 BUGFIX_VER=0 LIBS= include ../../Makefile.libs ...
The above example is from trie library, which will result on Linux in an object file libtrie.1.0.0.so.
Other Makefile variables such as DEFS or SER_LIBS can be used for libraries in the same manner as for modules. For example, an internal library can depend on another internal library - simply add the dependency to SER_LIBS variable.
The source code and headers have to be placed in files inside library's directory. There is no real restriction of what you can have inside, besides valid C code. however, it is recommended to use a naming pattern for C functions and global variables that will reduce the risk of naming conflicts.
A good practice is to declare only static global variables and export functions that give access (read/write) to them. Exported functions (non-static functions) should be prefixed by a token that tries to suggest the library and build an unique name. If you look inside trie library, the lib/tree/dtree.c file, all the functions are prefixed with dtree_.
To use a library, include the files with the prototypes of the functions that you need in your module and then use them where you need. In the Makefile of the module, you have to add the dependency on the respective library by setting accordingly the variable SER_LIBS. See Module Development section for more details on this topic.
Most of Kamailio source code is licensed under GPLv2. New development to be introduced in the public repository should have a GPLv2-compatible license. The copyright for major developments is developer's choice, either the developer, the company is working for or someone else.
Note that starting with v3.0.0, the contributions done to core components and main modules (tm, sl, auth) have to be done under BSD license. This was decided when integration of Kamailio and SER projects started in order to avoid conflicts between original developers and new ones.
If the code includes parts having other license make sure it is compatible with the GPLv2 and the way it is used now does not violate the original license and the copyright.
Each C source file that is added under GPLv2 must include a header as follows:
... /** * Copyright (C) YEARS OWNER * * This file is part of Kamailio, a free SIP server. * * kamailio is free software; you can redistribute it and/or modify * it under the terms of the GNU General Public License as published by * the Free Software Foundation; either version 2 of the License, or * (at your option) any later version * * kamailio is distributed in the hope that it will be useful, * but WITHOUT ANY WARRANTY; without even the implied warranty of * MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the * GNU General Public License for more details. * * You should have received a copy of the GNU General Public License * along with this program; if not, write to the Free Software * Foundation, Inc., 59 Temple Place, Suite 330, Boston, MA 02111-1307 USA */ ...
Each C source file that is added under BSD license must include a header as follows:
... /** * Copyright (C) YEARS OWNER * * This file is part of Kamailio, a free SIP server. * * Permission to use, copy, modify, and distribute this software for any * purpose with or without fee is hereby granted, provided that the above * copyright notice and this permission notice appear in all copies. * * THE SOFTWARE IS PROVIDED "AS IS" AND THE AUTHOR DISCLAIMS ALL WARRANTIES * WITH REGARD TO THIS SOFTWARE INCLUDING ALL IMPLIED WARRANTIES OF * MERCHANTABILITY AND FITNESS. IN NO EVENT SHALL THE AUTHOR BE LIABLE FOR * ANY SPECIAL, DIRECT, INDIRECT, OR CONSEQUENTIAL DAMAGES OR ANY DAMAGES * WHATSOEVER RESULTING FROM LOSS OF USE, DATA OR PROFITS, WHETHER IN AN * ACTION OF CONTRACT, NEGLIGENCE OR OTHER TORTIOUS ACTION, ARISING OUT OF * OR IN CONNECTION WITH THE USE OR PERFORMANCE OF THIS SOFTWARE. */ ...
YEARS and OWNER to be replaced appropriately.
Kamailio Home Page - http://www.kamailio.org
ASIPTO Home Page - http://www.asipto.com
Kamailio Dokuwiki Page - http://www.kamailio.org/wiki
Kamailio Documentation Repository - http://www.kamailio.org/w/documentation/
Kamailio Modules Documentation - http://www.kamailio.net/docs/modules
Kamailio Core CookBbook - http://www.kamailio.org/wiki/cookbooks/3.2.x/core
Kamailio and Asterisk Realtime Integration - http://kb.asipto.com/asterisk:realtime:kamailio-3.1.x-asterisk-1.6.2-astdb
Kamailio and FreeSWITCH Integration - http://kb.asipto.com/freeswitch:kamailio-3.1.x-freeswitch-1.0.6d-sbc
Kamailio GIT Repository (sub-project 'sip-router') - http://git.sip-router.org/
Kamailio Tracker - http://sip-router.org/tracker
Kamailio Users Mailing List - http://lists.sip-router.org/cgi-bin/mailman/listinfo/sr-users
Kamailio Devel Mailing List - http://lists.sip-router.org/cgi-bin/mailman/listinfo/sr-dev
SIP RFC 3261 - http://www.ietf.org/rfc/rfc3261.txt
The authors can be contacted via coordinates provided at www.asipto.com.
The tutorial is going to be included in the Kamailio repository, if you want to post messages with improvements or mistakes you can write emails to <sr-dev [at] lists [dot] sip-router [dot] org> or use the documentation tracker from sip-router.org.